Executive Summary:
Machine learning techniques called “multi-output classification” can predict many outcomes simultaneously. After making any predictions, the model will provide two or more outputs in multi-output classification. However, the model typically predicts just one outcome in other classification types. In this blog, we’ll check the methods for utilizing multi-output datasets in machine learning solutions.
Introduction:
Classification (binary and multiclass) and regression are the two common machine-learning problems everyone knows about. In these situations, we are attempting to forecast one target column. However, there are multiple target columns in the multi output scenario, and we want to train a model that can predict all of them simultaneously. Therefore, we recognize three categories of multi output tasks:
- Multilabel: Multilabel is a classification task that predicts properties of a sample, such as topics relevant to a text document.
- Multiclass-multioutput: Multiclass-multioutput is a classification task
that labels each sample with a set of non-binary properties, with a maximum number of properties and classes of 2.
- MultiOutput regression: Multi Output regression predicts multiple numerical properties for each sample, such as wind speed and direction.
In this example, we’ll describe how the ATOM library can make your pipelines on multi output datasets faster. The preparation of data, model training, model validation, and outcome analysis. Data scientists can explore machine learning solutions pipelines with ATOM, an open-source Python programme.

Data preparation
Starting a multi output dataset in an atom is similar to starting any other task with one exception. It would be best if you defined the target columns using the keyword argument y.
atom = ATOMClassifier(X, y=y, verbose=2, random_state=1)
If y= is omitted, the atom will interpret the second input as the test set, as if the initialization had been done with the syntax atom = ATOMClassifier(train, test) and throw a column mismatch error.
You can also supply a list of column names or locations to specify the target columns in X. Use this as an example to designate the final three columns as the target:
atom = ATOMClassifier(X, y=(-3, -2, -1), verbose=2, random_state=1)
Whenever possible, print oneself. Instead of the target of type Series, x now returns the target of type DataFrame.
The target column for jobs with several labels can resemble this.
0 [politics]
1 [religion, finance]
2 [politics, finance, education]
3 []
4 [finance]
5 [finance, religion]
6 [finance]
7 [religion, finance]
8 [education]
9 [finance, religion, politics]
Name: target, dtype: object
A model cannot directly ingest a variable number of target classes. Instead, use the clean technique to assign a binary output to each class for each sample. Positive classes are denoted by 1, whereas negative classes are denoted by 0. Doing n-classes binary classification tasks can be compared to this.
atom.clean()
The target (atom.y) in our case is transformed into:
education finance politics religion
0 0 0 1 0
1 0 1 0 1
2 1 1 1 0
3 0 0 0 0
4 0 1 0 0
5 0 1 0 1
6 0 1 0 0
7 0 1 0 1
8 1 0 0 0
9 0 1 1 1
Training and validation of models
Some models natively support multi output jobs. In other words, all target columns are directly predicted using the original estimate.
However, most models need more comprehensive support for multi output jobs. By encasing the estimators in a meta-estimator that can handle numerous target columns, ATOM still makes using them possible. Furthermore, this is carried out automatically without additional programming or user input.
ClassifierChain
The default meta-estimators for multiclass-multioutput and multi output regression tasks are, respectively:
MultioutputRegressor
The meta-estimator object is contained in the multi output attribute. Use a custom object by altering the value of the attribute. The underlying estimator can be the initial parameter in either classes or situations. For regression models, for instance, use the following to modify the meta-estimator:
from sklearn.multioutput import RegressorChain
atom.multioutput = RegressorChain
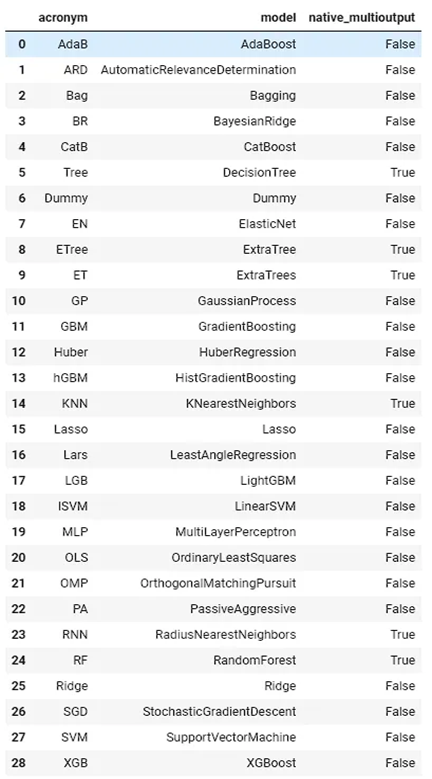
Use the following to determine which models natively handle multioutput datasets and which do not:
atom.available_model()[[“acronym”, “model”, “native_multioutput”]]
The models can now be trained normally.
atom.run(models=[“LDA”, “RF”], metric=“f1”)
Moreover, check the estimators.

While some models, like the MultiLayer Perceptron, have the natural capability for multilabel jobs, they do not. Because of this, their native multioutput tag is False; however, if you have a multilabel job, those models don’t necessarily need a multioutput meta-estimator. Use the atom’s multioutput attribute to instruct the atom not to employ multioutput wrappers in such circumstances.
atom.multioutput = None
# MLP won’t use a meta-estimator wrapper now
atom.run(models=[“MLP”])
Conclusion:
In conclusion, multi-output datasets are a powerful tool in machine learning, allowing us to predict multiple outcomes simultaneously. With the techniques and strategies we’ve discussed, you can effectively utilize these datasets in your own projects and achieve more accurate predictions. If you’re looking for high-quality image classification datasets using machine learning, check out our blog post on the topic. By incorporating multi-output datasets and other advanced techniques into your machine learning solutions, you can stay ahead of the curve and unlock new insights and opportunities for your business.
FAQs:
What is a multioutput classifier example?
A classification model that simultaneously predicts fruit type and color illustrates a multi-output classification model. Fruit varieties include orange, mango, and pineapple. Red, green, yellow, and orange are all possible color choices. This issue is resolved by the multi-output classification, which provides two predictions.
What is the process of multioutput regression?
Regression with multiple outputs forecasts two or more numerical variables. Multi-output regression requires specific machine learning algorithms that support outputting many variables for each prediction, unlike normal regression, which predicts a single value for each sample.
How can I integrate different machine learning models?
Ensemble and hybrid models are the methods used in machine learning solutions to combine models. Instead of just one machine learning algorithm, ensemble models combine several algorithms to get better-predicted outcomes.
What does machine learning mean by multimodal?
The term “multimodal learning” refers to a machine learning solution in which the model is trained to comprehend and process various types of input data, such as text, images, and audio. These various data kinds reflect the various modalities of the world or how it is perceived.