




In computer vision, image classification plays a vital role in various applications, from object recognition to scene understanding. Access to diverse and well-curated datasets is necessary to effectively train and evaluate classification models. This blog post will delve into several essential image datasets tailored for classification tasks, providing valuable insights into their characteristics and applications.
Introduction:
The most important part of any machine learning (ML) project is collecting good datasets, including good labels.
The datasets help train machines to perform techniques like image classification. When image classification datasets feed data to ML tools, they train them to emulate human cognitive abilities to extract meaning from images.
![]()
But where do we get these datasets?
We either create new or use existing datasets for training models. To create new datasets, we need tons of labeled image data. Since building a new image classification dataset is time-consuming, beginners tend to use existing datasets to get their tools up and running fast.
Image Classification Datasets
What is an Image Classification Dataset?
An image classification dataset is a curated set of digital photos used for training, testing, and evaluating the performance of machine learning algorithms.
Since the algorithms learn from the example images in the datasets, the images need to be high-quality, diverse, and multi-dimensional.
In the turn of these high-quality images, we get a high-quality training dataset that can perform classification accurately and expedite the decision-making process.
This is why it is crucial to pick a reliable training dataset that enhances the classification results.
Top 14 Machine Learning Image Classification Datasets
We have grouped these eight datasets into two categories: agriculture and scene datasets and medicine datasets, based on the type of images they contain.
Image Classification Datasets for Agriculture and Scene
1. MIT Indoor Scenes
This image classification dataset is developed for indoor scene recognition. It features more than 15,000 images of indoor locations and 67 separate indoor categories.
Though the number of images across categories varies, at least 100 images are in each category. The format of all images is JPG.
2. Intel Image Classification
Initially compiled and designed by Intel for a classification challenge, this image classification dataset has nearly 25,000 images of natural scenes worldwide.
Each image size is 150×150, available in categories such as mountain, glacier, sea, forest, buildings, and street.
The dataset also provides a collection of images for training, testing, and prediction in separate folders. Depending on the function you are preparing your model for, you can access relevant zip files of images.
These images can help you build a powerful neural network that can accurately classify images for any computer vision task.
3. Images for Weather Recognition
By providing images for any weather recognition project, this dataset helps classify images based on weather. It features a sum of 1125 images under categories such as sunny, cloudy, and rainy.
4. TensorFlow Sun397
Sun397 is an extensive Scene UNderstanding (SUN) dataset featuring 108,753 images classified into 397 categories.
These categories help evaluate numerous algorithms for scene recognition. While the categories contain a different number of images, they have a minimum of 100 images in each category.
There are also some other configurations of this dataset available with 76,000+ training images, more than 10,000 validation images, and a little over 21,000 test images.
Image Classification Datasets for Medicine
1. TensorFlow Patch_camelyon
PatchCamelyon is a medical image classification dataset consisting of 327,000+ color images extracted from histopathological lymph node scans.
They are 96×96 pixel images annotated to indicate the presence of metastatic tissue.
Being a new and challenging dataset, PatchCamelyon creates a unique benchmark for machine learning models.
2. Blood Cell Images
The dataset comprises 12,500 augmented images of blood cells alongside labels for four cell types. Each cell type has approximately 3,000 images gathered in 4 different folders based on cell type.
Another dataset consists of 410 images (pre-augmentation), two blood cell subtype labels: WBC and RBC, and bounding boxes for each cell in each image.
These datasets can help prepare models for automated diagnosis of blood-based diseases by detecting and classifying blood cell subtypes.
3. Recursion Cellular Image Classification
The data in this dataset is from the results of the Recursion Cellular Image Classification competition.
This cellular image classification dataset can help make better inferences on the state of body cells to help us discover treatments for a wide range of diseases.
4. ChestX-ray8
ChestX-ray8 is a medical imaging dataset that contains 108,948 frontal-view X-ray images collected from 1992 to 2015.
The x-ray images belong to 32,717 unique patients. Images also contain text-mined labels of eight common diseases extracted from text radiological reports.
Image Datasets for Image Classification
1. ImageNet:
ImageNet is a vast annotated image dataset used extensively in computer vision research.
- Image-level annotations
It contains image-level annotations indicating the presence or absence of object classes within images, as well as
- Object-level annotations
Object-level annotations provide bounding boxes and class labels around object instances.
ImageNet’s specialty lies in its comprehensive coverage of visual concepts, making it a valuable resource for training and evaluating image classification models.
Data set Details:
- 14,197,122 images
- 21,841 WordNet synonym sets
- 1,034,908 annotated images with bounding boxes
- 1000 synsets with scale-invariant feature transform (SIFT) features
- 1.2 million images with SIFT features

Source: https://cs.stanford.edu/people/karpathy/cnnembed/cnn_embed_1k.jpg
2. CIFAR-10
CIFAR-10 is a well-known dataset comprising 60,000 color images distributed evenly across ten classes, including airplanes, cars, and animals. Its specialty lies in its suitability for quickly testing and benchmarking image classification algorithms, thanks to its low-resolution images and diverse class distribution.
Data set Details:
- Collection of training images designed for computer vision projects.
- Comprises 60,000 color images distributed across 10 classes, including
- Airplanes
- Cars
- Trucks
- Ships
- Birds
- Cats
- Dogs
- Deer
- Frogs
- Horses
Official dataset page:https://www.cs.toronto.edu/~kriz/cifar.html
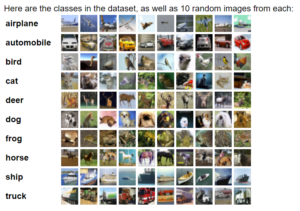
Source: https://www.cs.toronto.edu/~kriz/cifar.html
3. ObjectNet
ObjectNet is a unique dataset consisting of test images collected via crowd-sourcing. It features objects captured in realistic, cluttered scenes, challenging the performance of object recognition algorithms. ObjectNet’s specialty lies in its focus on testing the robustness of algorithms trained with transfer learning, making it an ideal benchmark for evaluating algorithm performance in real-world scenarios.
- 50,000 test images with rotation, viewpoint, and background controls
- 313 different object classes (113 of which classes overlap with ImageNet)
Official dataset page:https://objectnet.dev/

Source: https://objectnet.dev/
4. MIT Indoor Scenes
MIT Indoor Scenes is a dataset developed to address the challenge of machine perception in indoor environments. It contains over 15,000 images categorized into 67 indoor scene categories. Its specialty lies in its focus on indoor scene recognition, providing valuable data for developing models tailored for indoor settings.
- Dataset details:
- 15,620 images
- 67 indoor scene categories
- At least 100 JPEG images per category
Official dataset page: https://web.mit.edu/torralba/www/indoor.html

Source: https://web.mit.edu/torralba/www/indoor.html
5. Scene Understanding (SUN) Database
The SUN Database is a large-scale dataset containing over 100,000 images across 397 categories. Its specialty lies in its use for scene categorization research, offering a diverse range of scene types and categories for training and evaluating scene understanding models.
- Dataset details:
- 108,753 images, divided into
- 76,128 training images
- 10,875 validation images
- 21,750 test images
- 397 categories
- At least 100 JPEG images per category
- At most 120,000 pixels per image
Official dataset page: https://vision.princeton.edu/projects/2010/SUN/
Architectural Heritage Elements (AHE): The AHE dataset focuses on architectural image classification tasks and features ten categories, including altar, dome, and stained glass. Its specialty lies in its suitability for training algorithms to recognize architectural elements in images, making it valuable for cultural heritage preservation and architectural analysis.
- Dataset Details:
- 829 altar images
- 514 apse images
- 1059 bell tower images
- 1919 column images
- 1793 dome images
- 407 flying buttress images
- 1571 Gargoyle images
- 1033 stained glass images
- 1100 vault images
Official dataset page: https://old.datahub.io/dataset/architectural-heritage-elements-image-dataset

Source: https://vision.princeton.edu/projects/2010/SUN/
6. Intel Image Classification
The Intel Image Classification dataset focuses on natural scene classification and contains approximately 25,000 images grouped into categories such as buildings, forests, and mountains. Its specialty lies in its application for training and testing image classification models across different real-world environmental scenarios.
- Dataset Details:
- Approximately 25,000 images
- Images are grouped into categories such as buildings, forests, glaciers, mountains, seas, and streets.
- The dataset is divided into folders for training, testing, and prediction:
- 14,000 training images
- 3,000 validation images
- 7,000 test images
Official dataset page: https://www.kaggle.com/puneet6060/intel-image-classification

Source: https://www.researchgate.net/figure/Dataset-samples-of-Cultural-Heritage-images-used_tbl1_320052364
By leveraging these diverse image datasets, researchers and practitioners can train, validate, and benchmark their classification models effectively. Whether exploring novel algorithms or evaluating existing approaches, the availability of high-quality datasets is essential for driving advancements in computer vision technology.
How to Build a Dataset for Image Classification:
Building a dataset for image classification involves gathering a collection of images that represent the categories you want your model to recognize. Here’s a step-by-step guide:
- Define Your Categories: Determine the distinct categories or classes you want your model to classify images into. For example, if you’re building a model to recognize animals, your categories might include cats, dogs, birds, etc.
- Gather Images: Collect a diverse set of images that belong to each category. These images should accurately represent the variability within each class.
- Preprocess Images: Standardize the size, format, and quality of the images in your dataset. Ensure consistency across all images to prevent biases in your model.
- Split Your Dataset: Divide your dataset into training, validation, and testing sets. The training set is used to train your model, the validation set is used to tune hyperparameters and evaluate performance during training, and the testing set is used to assess the final performance of your model.
- Augment Your Data (Optional): Data augmentation techniques such as rotation, flipping, and cropping can be applied to increase the diversity of your dataset and improve the generalization ability of your model.
- Annotate Your Data: Label each image with its corresponding category or class. This annotation process is crucial for supervised learning, where the model learns to associate images with their correct labels.
- Ensure Data Quality: Verify the accuracy and consistency of your annotations to avoid errors that could negatively impact your model’s performance.
- Regularly Update Your Dataset: As your model evolves and new categories or classes emerge, continue to update and expand your dataset to improve the robustness and versatility of your model.
How to Design Classes and Labels:
Designing classes and labels involves defining the characteristics and attributes of each category in your dataset. Here are some key considerations:
Number of Labels: Determine the number of distinct labels or categories your dataset will include. This could range from a few broad classes to hundreds of fine-grained categories, depending on the complexity of your classification task.
Granularity Within Labels: Decide how specific or detailed each label should be. Some classifiers may require coarse distinctions (e.g., differentiating between broad object categories like animals and vehicles), while others may demand fine-grained classifications (e.g., identifying specific species of animals).
Detection Criteria: Establish the conditions under which an object should be classified into a particular category. Consider factors such as object occlusion, pose variation, and lighting conditions, and determine whether your model should classify objects under these diverse circumstances.
Definition of Labels: Clearly define the characteristics and attributes that distinguish one label from another. Provide specific criteria for labeling objects to ensure consistency across all images and minimize ambiguity in your dataset.
By carefully designing your classes and labels and building a comprehensive dataset, you can train accurate and reliable image classification models capable of recognizing and categorizing objects with high precision.
End Note:
In conclusion, building a dataset for image classification involves careful planning and consideration of various factors such as defining classes, annotating images, and ensuring data quality. However, for those looking for quicker and easier solutions, pre-defined datasets offer a convenient option. These datasets come with pre-labeled images across a wide range of categories, saving time and effort in dataset creation. By leveraging these pre-defined datasets, researchers and practitioners can kickstart their image classification projects more efficiently, focusing on model development and experimentation rather than data collection. Whether building a custom dataset or utilizing pre-defined ones, the ultimate goal remains the same: to train accurate and reliable image classification models capable of effectively categorizing diverse visual content

Dawood is a digital marketing pro and AI/ML enthusiast. His blogs on Folio3 AI are a blend of marketing and tech brilliance. Dawood’s knack for making AI engaging for users sets his content apart, offering a unique and insightful take on the dynamic intersection of marketing and cutting-edge technology.




