Executive Summary:
Even though machines have improved intelligence in recent years, they can only distinguish between similar objects with a labeled data collection of visible classes. This is called the zero-shot learning problem (ZSL) in machine learning.
This blog will describe zero-shot learning, how it functions, and other pertinent information. Learn more and take a knowledge test by reading on.

Introduction:
An essential tool of artificial intelligence today is deep learning. Among its various uses, it is currently frequently applied to address challenging Computer Vision problems using supervised learning.
However—Under this paradigm for learning, some strategies are restricted.
One needs many labeled training cases to train a robust model in supervised classification (for each class).
Additionally, the trained classifier can only classify cases that fall into the training data’s classes; it cannot cope with previously observed classes.
Furthermore, we can acquire new data gradually rather than all at once. However, deep learning models must be trained using a lot of computer resources and time, and it is frequently challenging to retrain such models from scratch to incorporate the most recent data.
“Zero-Shot Learning” (ZSL) can help in this situation.
We’ll review all you need about zero-shot learning in the next few minutes.
Zero-Shot Learning: What is it?
Without prior training for those classes, Zero-Shot Learning (ZSL), a machine learning technique, enables a model to categorize objects from previously unknown classes. This method is helpful for autonomous systems that can independently recognize and classify new things.
Zero-Shot Learning asks a model to generalize to a different collection of classes (unseen classes) without any extra training once it has been trained on a set of classes (seen classes). ZSL’s objective is to use the knowledge already included in the model to classify as-yet-undiscovered classes. Transfer learning, which involves adapting a model to a new task or set of classes, is a field that includes ZSL.
Homogeneous transfer learning, in which both feature and label spaces are the same, and heterogeneous transfer learning, in which the feature and label spaces are different, are the two types of transfer learning. ZSL belongs to the latter group.
The Value of Zero-shot Learning
- Scarcity of Data
As previously indicated, high quantity and quality data are difficult to come by. Machines need input labeled data to learn and then be able to adjust to variations that may naturally arise, unlike humans, who have zero-shot learning ability.
Consider how many different animal species there are. It will be challenging to maintain annotated data collection if more categories are added to other domains.
This has increased the value of zero-shot learning for us. To make up for the shortage of data, more and more researchers are becoming interested in automatic attribute recognition.
- Data Labeling
Zero-shot learning also has strong data labeling capabilities. However, data labeling can be labor-intensive and tiresome, increasing the risk of mistakes. In addition, data labeling is a time- and money-consuming process that involves experts, such as doctors working on a biomedical dataset.
What is the process of zero-shot learning?
The following data is used in zero-shot learning:
- Seen classes: The data classes used to train the deep learning model are known as Seen Classes.
- Unseen Classes: The current deep model needs to generalize these data classes. These classes’ data weren’t used at all during training.
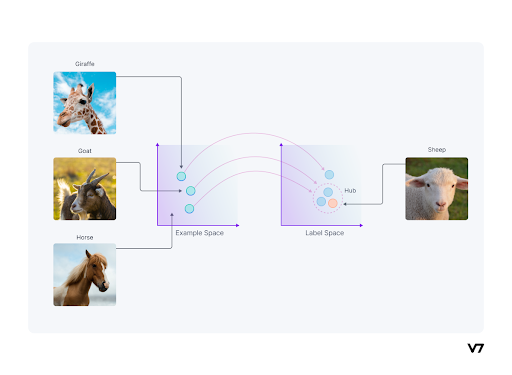
- Auxiliary Information: Some auxiliary information is required to solve the Zero-Shot Learning issue because no labeled examples of the unseen classes are accessible. Such auxiliary information, which may take the form of word embeddings, semantic information, or descriptions, should provide details about all of the classes that are not visible.
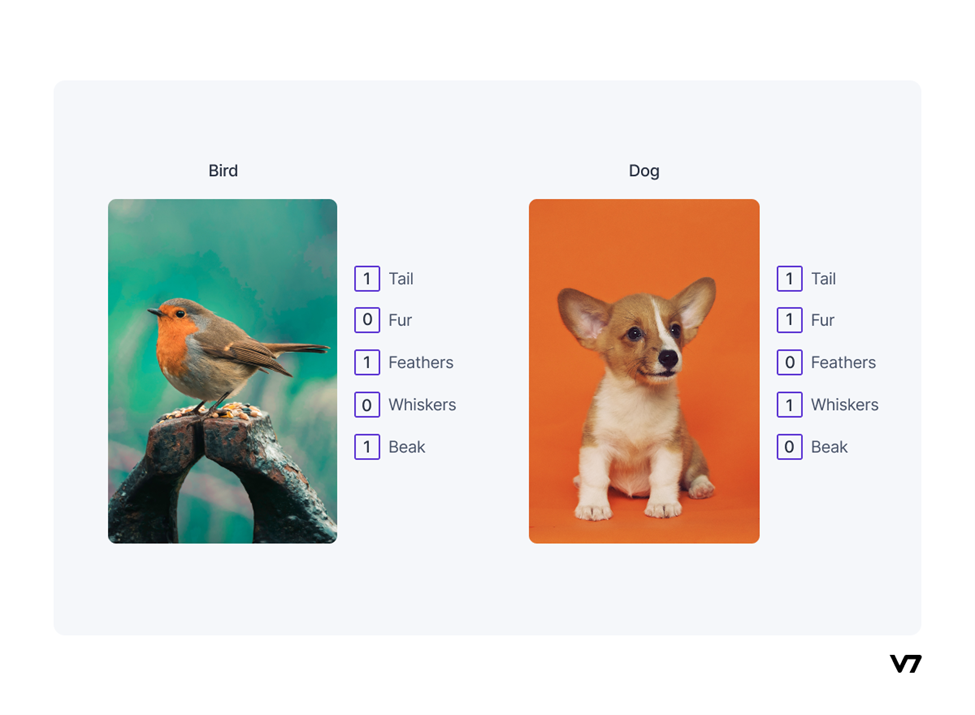
Example of semantic embedding using an attribute vector
Zero-Shot Learning, at its most basic, is a two-stage procedure requiring training and inference:
- Training: Information is learned about the labeled sample set of data.
- Inference: The previously gained knowledge is expanded, and the additional information given is applied to the new set of classes.
The findings of this study suggest that humans are capable of zero-shot learning because of their pre-existing language knowledge base (training), which offers a high-level description of a novel or unseen class and draws connections between this unseen class, visible classes, and visual concepts.
In simple words—
Humans intuitively notice similarities across different data classes, such as dogs and cats having four legs and tails.
A labeled training set of seen and unseen classes is another component of Zero-Shot Learning. The knowledge from seen classes can be used for unseen classes because both seen and unseen classes are related in a high-dimensional vector space called semantic space.
The obstacles of zero-shot learning
Grasp the main obstacles that zero-shot recognition faces is crucial for developing a greater grasp of the paradigm and formulating solutions.
Let’s examine several issues with Zero-Shot Learning classification that are crucial to a model’s success.
- Domain change
Domain shift is a crucial component of zero-shot since it influences how well a deep network generalizes to classes not present in the distribution.
- Transfer of knowledge across domains
Cross-domain knowledge transfer from the semantic to the visual domains is required to recognize visual features from classes that have yet to be seen.
- Bias
Zero-shot learning models have a bias in favor of seen classes, which causes them to classify images of unseen classes, lowering recognition performance incorrectly.
- Hubness
When a high-dimensional vector is projected into a low-dimensional space, hubness lowers variance, and groups mapped points as hubs. Performing the nearest neighbor search in semantic space impacts zero-shot performance.
Conclusion:
Zero-Shot Learning is a very recent field of study, yet it is undeniably one of the most important research areas in computer vision and has a very high potential.
It can serve as the foundation for a variety of projects in the future: Using Zero-Shot learning, a helper-embedded system for visually impaired people can be created. In addition, zero-Shot learning can be used with security cameras to count and identify unusual species in their natural habitat.
We are attempting to create robots that are comparable to ourselves with the advancements in robotics.
We want to give robots the ability to see, one of the most significant traits that make people human. Even if we have never seen a sample of an object, we can still interpret and recognize it since we can at least infer what it is. Since the Zero-Shot learning method shares many characteristics with the human visual system, it can be applied to robot vision. Zero-Shot learning makes recognizing everything in the world feasible instead of only a few.