AI Data Extraction Solution for Enterprise Documentation
Turn unstructured documents into validated, structured data automatically with AI built for enterprise scale, accuracy, and seamless system integration.
Turn unstructured documents into validated, structured data automatically with AI built for enterprise scale, accuracy, and seamless system integration.
Manual document workflows introduce delays, errors, and operational bottlenecks that compound across every team, system, and business process they touch.

Inconsistent field formats and missing values corrupt downstream databases, triggering costly remediation cycles across every connected system and reporting layer.

Teams expend significant hours on manual data entry from documents — time that would otherwise be directed toward higher-value analytical and operational work.

Conventional OCR degrades on scanned files, non-standard layouts, and handwritten content, producing raw output that still demands manual correction before it is usable.

Document volume growth demands proportional headcount growth. Without AI-driven automation, organizations have no viable mechanism to increase throughput without expanding their manual processing teams.

Ingests PDFs, Word documents, spreadsheets, emails, images, and scanned files through a unified pipeline — with no requirement for format-specific connectors or pre-processors.
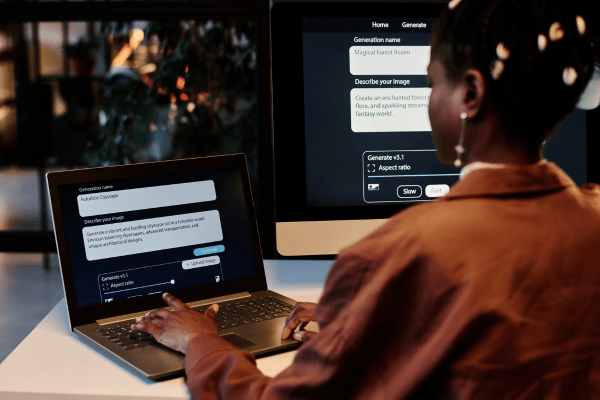
The AI interprets document context rather than matching against templates, enabling new document types to be onboarded in minutes rather than days.

Accurately captures multi-row line items, nested table structures, and merged cells — data patterns that consistently exceed the capabilities of conventional OCR tools.
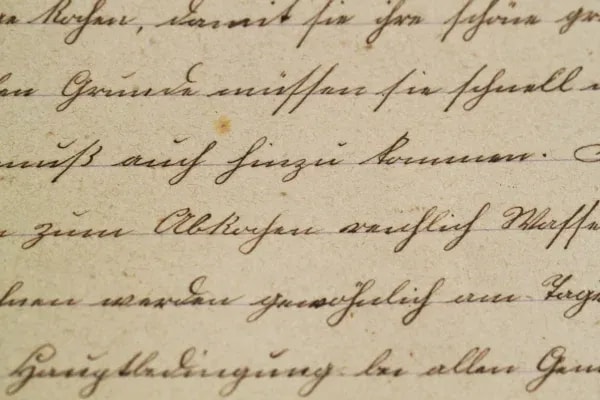
Identifies and extracts handwritten annotations, rubber stamps, authorization signatures, and embedded visual data that text-only extraction pipelines are unable to process.

Processes documents in 200+ languages, including Arabic, Mandarin, Hindi, and Cyrillic scripts, with extraction accuracy equivalent to Latin-script document performance.

Applies configurable normalization rules to standardize date formats, currency values, telephone numbers, and units of measure consistently across all ingested documents.

Each extracted field is assigned a confidence score. Values below defined thresholds are held in a reviewer queue — ensuring only verified data reaches downstream systems.

Processes thousands of documents per hour through a horizontally scalable architecture designed to sustain performance and accuracy during peak ingestion periods.

Delivers validated data as JSON, CSV, or Excel, and transmits directly to enterprise platforms via REST API, webhooks, or pre-built connector libraries.
A four-step pipeline that ingests, interprets, validates, and delivers structured document data — directly into your existing systems, without manual intervention.

Specify the data points the system should extract, like invoice amounts, patient identifiers, and contract dates. No template configuration or model training is required.

Ingest PDFs, scanned images, emails, or Word files through API or direct upload. The AI processes each document regardless of layout, language, or input quality.
Retrieved fields are delivered with confidence scores. Low-confidence values are automatically routed to a human review queue before downstream delivery.

Validated data is transmitted to your ERP, CRM, or database via REST API or pre-built connectors, eliminating manual export and re-entry at every stage.
Extracts vendor identifiers, line-item detail, tax values, PO references, and payment terms — reliably across every supplier template and invoice format encountered.
Isolates parties, effective dates, contractual obligations, defined terms, and amendment clauses to support legal review, obligation tracking, and contract lifecycle management.
Parses candidate profiles, like name, contact information, employment history, educational credentials, and skills, into structured records compatible with ATS and HRMS platforms.
Extracts account numbers, transaction records, opening and closing balances, and period summaries from statements across geographies, institutions, and reporting formats.
Processes patient demographics, diagnostic codes, medication records, lab results, and clinical annotations within a PHI-compliant infrastructure aligned to HIPAA requirements.
Captures shipment identifiers, consignee data, cargo descriptions, port codes, and delivery terms from bills of lading, packing lists, and customs declarations.
Extracts data from tables, charts, abstracts, and cited references across scientific, financial, and market research documents at a batch scale.
Parses inbound message content and attached documents in parallel, extracting order details, inquiry data, and structured fields without manual triage or routing.
Automates extraction from loan applications, KYC documentation, trade confirmations, and financial statements, reducing processing overhead and compliance exposure simultaneously.
Processes clinical trial records, electronic health data, insurance claims, and regulatory submissions within PHI-safe infrastructure aligned to HIPAA and FDA documentation standards.
Extracts parties, obligations, key dates, and defined terms from contracts, discovery files, and regulatory filings, enabling legal teams to focus on substantive analysis.
Automates data capture across bills of lading, customs declarations, freight invoices, and delivery documentation to eliminate manual entry across the logistics network.
Structures resumes, onboarding forms, policy acknowledgments, and compliance documents into normalized records that integrate directly with existing HRMS and ATS environments.
Processes supplier invoices, product catalog files, return authorizations, and purchase orders at the throughput and volume enterprise retail operations require.
Extracts data from claims submissions, policy documents, medical records, and adjuster reports to accelerate underwriting, claims adjudication, and fraud detection programs.
Automates ingestion of inspection reports, equipment certifications, work orders, and supplier quality documentation to maintain data integrity across ERP and QMS platforms.

Independently audited controls covering operational security, incident response, and change management across the full infrastructure scope of our extraction platform.

Data residency controls, right-to-erasure mechanisms, and DPA-ready documentation to support your obligations under European data protection regulation.
-27f42b19-7ef8-44e6-a1a0-0e4d03a2e035.png&w=1920&q=65)
PHI-compliant infrastructure with access controls, audit logging, and data handling procedures appropriate for healthcare organizations processing clinical and patient documentation.

Customer documents and extracted data are processed within a fully isolated infrastructure. No data is shared across tenants or used to train shared AI models.

Outcomes
Extraction pipelines are trained and configured against your actual document corpus — ensuring accuracy on the edge cases and format variations your organization encounters.
Field validation rules, confidence thresholds, and normalization transforms are implemented to your business specifications — not inherited from a generic SaaS product.
Connectors for SAP, Salesforce, proprietary ERPs, and custom internal databases are built as part of the engagement, eliminating middleware gaps and manual export steps.
Extraction accuracy compounds over time as the model is refined against reviewed exceptions and corrections from your team — a capability unavailable in static SaaS tools.
Template-based rules that break when document layouts shift
LLM-powered contextual understanding — adapts to any format automatically
Fails on layout changes, non-standard structures, and new formats
Processes any format or layout without reconfiguration or retraining
Plain text only — tables, stamps, and images are not captured
Text, tables, images, handwriting, stamps, and embedded visual data
Degrades sharply on scanned, low-resolution, or degraded inputs
Maintains high accuracy on scans, blurry inputs, and faxed documents
Extensive template configuration required per document type
Specify target fields, submit documents, and receive structured output
Limited — non-Latin scripts are largely unsupported
200+ languages, including Arabic, Chinese, Hindi, and Cyrillic scripts
Unstructured raw text requiring additional processing steps
Structured JSON, CSV, or Excel — validated and ready for immediate use
Redirect your teams from data entry to decision-making. Our AI data extraction solution delivers structured, validated output from every document you process.
Improve Search Across Every Team
Fill the form below or Contact us at +1 408 365-4638 / email us via contact@folio3.ai
Years of Engineering Excellence
Delivered Worldwide
Client Satisfaction
Years of Advanced AI Expertise
Response Guaranteed
+1 408 365-4638
contact@folio3.ai
6701 Koll Center Parkway, #250 Pleasanton, CA 94566