Executive Summary:
TLDR: Meta-learning is a useful technique for personalizing and optimizing the delivery of designs, content, products, campaigns, and messages for maximum benefit. This study introduces the concept of the Net Value Conditional Average Treatment Effect (Net Value CATE) and methods for estimating it using meta-learning. It also describes how Uber has designed its system to deliver causal uplift models at scale.
Consider that you want to send your users a message to optimize for a particular result, like a conversion. You can send the message through various channels, including email, push notifications, an onsite campaign, etc. However, it is expensive to deliver a message, and users react differently across mediums. The study addresses choosing the best channel for each user to get the best causally predicted uplift. It is broadly applicable to any decision-making situation with numerous heterogeneous cost treatments.
Those most likely to benefit from treatment can be identified via uplift modelling, and it is important to give them the preferred experience first. An experiment with numerous treatment groups with varied costs, such as when various communication channels and promotion styles are explored concurrently, is an important but underappreciated use case for uplift modelling.
Meta-Learners for the Neyman-Rubin framework of assessing uplift
The paper focuses on personalization and uses the Neyman-Rubin framework and a causal inference perspective. The conditional average treatment effect (CATE), the average treatment effect conditioned on user observables, is the estimand of interest in this case.
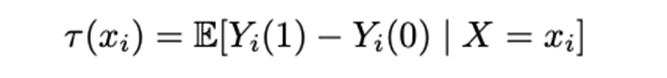
The equation mentioned above represents CATE, where tau(x i) is CATE for users with observables x i and Y i(1) and Y i(0) are possible outcomes for user I depending on whether she receives the treatment or not.
Because it enables them to comprehend how treatment effects vary based on the observable features of the population of interest, the CATE is relevant to researchers. Uplift modelling can be seen as estimating the CATE using machine learning solutions techniques.
How do we go about flexible CATE estimation now that we have identified what interests us? The study examines numerous meta-learners who have done this. These students typically go through several stages before coming together. The two-model strategy is among the most straightforward meta-learners. The estimator that utilizes two models
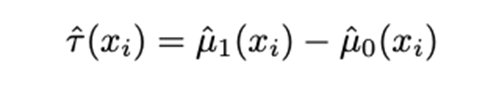
To estimate CATE, the conditional means for the treatment group (first term on the right side) and the control group (second term on the right side) are fitted separately and then combined. The fact that virtually any relevant model can be used for the conditional means is a benefit of this technique. The same is true for the more complex estimators examined in the research, X-learner and R-learner, both of which use a propensity score.
Expanding the learners to various treatment groups and expenses is known as the Net Value CATE.
By computing the conditional mean and propensity score for all accessible treatments, both required in the X- and R-learner, it is possible to extend the learners to multiple treatments. The conditional mean for treatment t j is more specific.
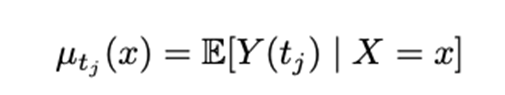
And the propensity score is
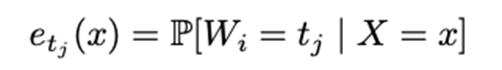
Again, estimating such quantities is possible using any appropriate model.
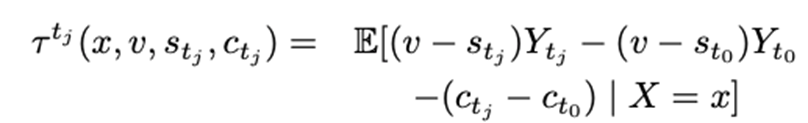
The study proposes the intriguing and pertinent idea of Net Value Optimisation, expressed as Net Value CATE: to account for expenses.
The value of a conversion, which is presumptively homogeneous across treatments, is reflected in the Net Value CATE by the variable v. s represents what the authors refer to as the “triggered cost” for a conversion, which might vary depending on the user and the therapy. This could reflect the value of the discount offered by a promotion, which may vary between promotions (treatments). Notably, payment is made only after conversion. Finally, c shows the average cost per impression for each user, which might vary among treatments and users and is unrelated to conversion. Y is the conversion tendency, as previously.
Analyzing Meta-Learner Performance for the Net Value CATE
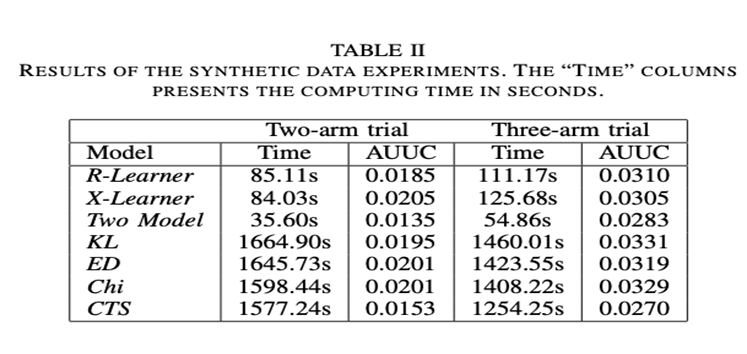
Cross-validation is typically difficult for assessing learning performance in causal inference problems since the counterfactual result is inherently unpredictable and needs a ground truth. Therefore, the authors employ the Area Under the Uplift Curve (AUCC) as an evaluation metric and apply the learners to synthetic and real-world data to gauge performance, following the discussion in this literature.
The observations in the machine learning solution testing set are sorted into 100 bins from the highest anticipated uplift to the lowest to construct this metric. We have about equal treatment and control observations in each bin because the treatment assignment is randomized. This enables us to compute the average treatment effect within each bin. If only the highest p bins in the treatment are subjected to the treatment condition, we determine the average difference between the treatment and the control. The approach with the highest AUUC is the one that performs the best in terms of this criterion.
According to Table II, the X-learner has the highest AUUC and is still computable in a reasonable amount of time. The comparison comprises decision-tree-based methods employing the Kullback-Leibler divergence (KL), the Euclidean distance (EL), the chi-squared divergence (Chi), and a contextual treatment selection (CTS) algorithm in addition to comparing several meta-learners.
The uplift curve and the use of the algorithms in the conversion optimization work support the previous finding.
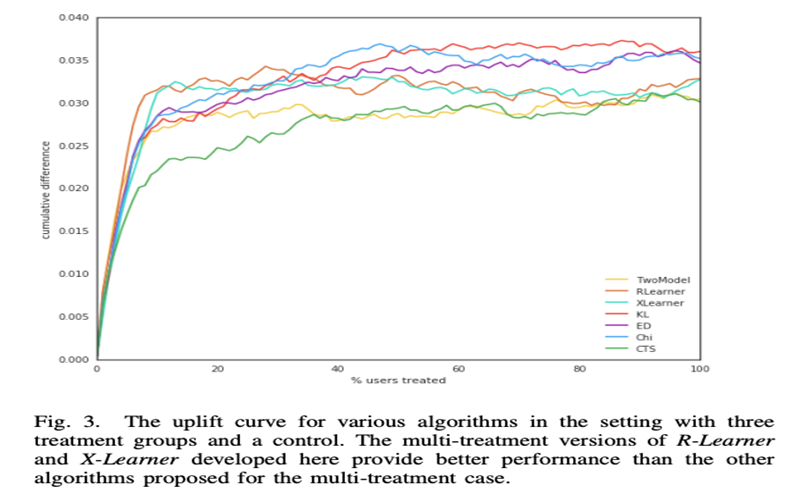
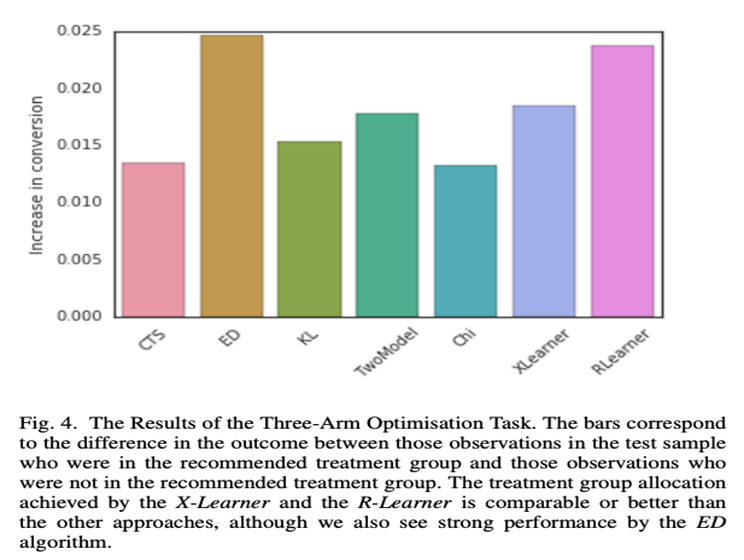
The authors conclude by achieving higher net values overall, which is unsurprising given that the net Net Value CATE precisely has this optimization goal. So the net Net Value CATE surpasses the ordinary CATE.
Platform Design Using Causal Uplift Modeling
The system design of Uber’s uplift modelling platform is described in the paper’s concluding section. The system generates user-level uplift ratings for various treatments using a target measure, features, and configuration as inputs. These scores can be delivered online, offline, or in a data repository.
FAQs:
What is cost-optimized uplift modelling for many treatments?
A new machine learning solution called uplift modelling can be used to estimate the treatment effect on an individual or subgroup level. It can be applied to enhance the effectiveness of interventions like advertising campaigns and product designs.
How do uplift modelling techniques work?
A causal learning method for evaluating the impact of each particular treatment in an experiment is called uplift modelling. For example, the end-user can determine the incremental influence of therapy (such as a direct marketing campaign) on a person’s behavior using experimental data.
What is the cost-optimized strategy?
Cost optimization is a business-focused, ongoing discipline that helps to maximize corporate value while driving spending and expense reduction. It is part of getting the best terms and prices for all business purchases. In addition, platforms, apps, workflows, and services should be standardized, simplified, and rationalized.
What role does cost optimization play?
Business leaders may budget and spend more wisely while investing in growth and digitalization using a strategic cost optimization approach.