


Executive Summary:
YOLO proposes using an edged neural network that provides predictions of bounding boxes and class probabilities as opposed to the strategy used by object detection algorithms before it, which repurposes classifiers to do detection, which is why it is the best model for person detection solutions.
YOLO significantly outperforms the performance of existing real-time object detection algorithms by using a fundamentally different approach to object detection.
Overview of Object Detection
The identification and localization of items within an image or a video are made using the object detection technique in computer vision services. Bounding boxes, rectangular forms surrounding the objects, are used in image localization to pinpoint the precise location of one or more items. This procedure is occasionally mistaken with image classification or recognition, which seeks to determine which category or class an image or an object contained inside a picture belongs to. The graphic that follows represents the previous explanation visually. “Person” is the object that can be found in the photograph.
In this blog post, you will learn about the best model for Object detection solutions, its application, its advantages, and much more.

What is YOLO exactly?
YOLO stands for You Only Look Once. Its algorithm recognizes and locates several elements in a picture (in real time). The object identification procedure in YOLO, treated as a regression problem, provides the class probabilities for the identified photos. The YOLO method recognizes items instantly using convolutional neural networks (CNN). As the names suggest, the technique needs one forward transmission through a neural network to detect objects and individuals. This implies that a single algorithm performs prediction throughout the entire image. Multiple bounding boxes and class probabilities are forecast simultaneously using CNN. The YOLO algorithm exists in a variety of distinct forms. Tiny YOLO and YOLOv3 are two of the better-known ones.
Why is YOLO so well-liked for object detection?
YOLO is ahead of the pack for some reasons, including its:
- Speed
- Detection accuracy
- Good generalization
- Open source
- Speed
Because it doesn’t deal with complicated pipelines, YOLO is incredibly quick. At 45 frames per second, it can process images (FPS). Since it can achieve double the Average Precision (mAP) compared to other real-time systems, YOLO is a superb option for real-time processing. Furthermore, with 91 FPS, YOLO is superior to other object detectors.
- High detection accuracy
With a meager amount of background mistakes, YOLO’s accuracy greatly outpaces that of other cutting-edge models.
- Open source
Making YOLO open source encouraged the neighborhood to enhance the model continuously. This is among the factors that have contributed to YOLO’s rapid rise.
Improved generalization
This is particularly true for the updated YOLO versions, which will be covered in more detail later in the text. With those improvements, YOLO went a little further and offered improved generalization for new domains, making it ideal for applications that require quick and reliable object identification.
The Automatic Detection of Melanoma with Yolo Deep Convolutional Neural Networks article, for instance, demonstrates that, when compared to YOLOv2 and YOLOv3, the first version of YOLOv1 has the lowest mean average precision for the automatic detection of melanoma disease.
YOLO Architecture
The GoogleNet architecture of YOLO is comparable. It has two fully connected layers, four max-pooling layers, and 24 convolutional layers.
This is how the architecture functions:
- Before passing the input image through the convolutional network, it is resized to 448×448.
- After a 1×1 convolution to minimize the number of channels, a 3×3 convolution produces a cuboidal output.
- Except for the final layer, which employs a linear activation function, the activation function used inside is ReLU.
- Additional methods like batch normalization and dropout, for example, regularise the model and stop it from overfitting, respectively.
You will be prepared to utilize Keras to train and test intricate, multi-output networks and further your understanding of deep learning once you have finished the Deep Learning in Python course.
How Does YOLO Object Detection Work?
The three techniques used by the YOLO algorithm are as follows:
- Residual or remaining blocks
- Box regression bounding
- IoU – Intersection Over Union
- Residual blocks
The image is first separated into several grids. The size of each grid is S x S. The grids created from an input image are displayed in the following image.

In the image ahead, there are many grid cells with identical dimensions. Each grid cell will have the ability to recognize objects that enter it. For instance, if an object’s center appears within a grid cell, the object will be detected in that cell.
- Regression with bounding boxes
An outline that draws attention to an object in a picture is called a bounding box.
The following characteristics are present in each bounding box in the image:
- Width (BW)
- Height (bh)
- The letter c represents class, including person, car, traffic signal, etc.
- Boxing in the middle (bx, by)
An illustration of a bounding box can be seen in the image below. A yellow outline serves as a representation of the bounding box.
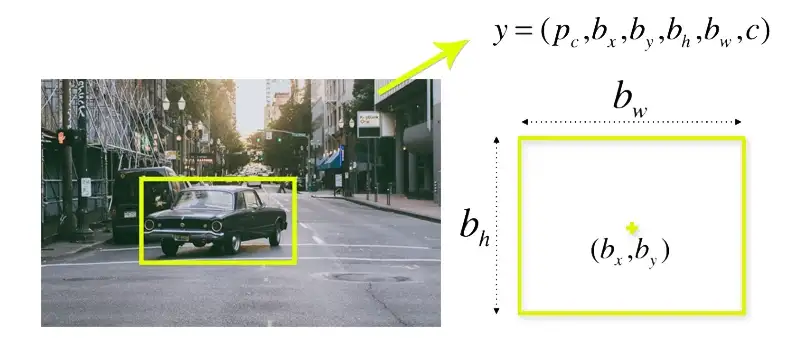
YOLO uses a solitary bounding box regression to establish an object’s height, breadth, center, and class. Reflects the likelihood of an object existing in the bounding box in the above image.
Navigating over a union (IOU)
The object and person detection solutions phenomenon known as intersection over union is used to explain box overlapping (IOU). These items are created by YOLO using OU. The projected bounding boxes and their confidence scores are responsible for each grid cell. The IOU equals if the actual and anticipated bounding is eliminated.
The following figure demonstrates how the IOU works.

The image displays two bounding boxes, one in blue and the other in green. The predicted box is blue, whereas the actual package is green.
Fusion of the three techniques
The three procedures are applied to create the final detection results, as seen in the accompanying image.
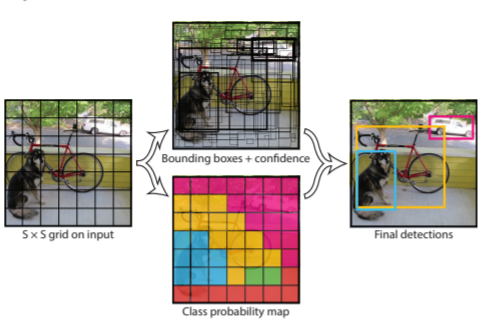
Grid cells are initially created from the image. In each grid cell, B boundary boxes and confidence ratings are anticipated. The cells project the class probability to identify each object’s class. For example, a bicycle, a dog, and a car are three objects that can be of at least three different sorts. All forecasts are made simultaneously by one fully convolutional. The intersection over the union ensures that the projected bounding boxes match the actual boxes of the items. Bounding boxes that are unnecessary or don’t match the characteristics of the items are removed because of this phenomenon (like height and width). The ultimate person detection solutions will have unique bounding boxes tailored specifically to the things. For instance, the pink bounding box encloses the car, whereas the yellow frame encloses the bike. The dog has been emphasized using the blue border box.
YOLO applications
The following fields can use the YOLO algorithm:
- Autonomous vehicle:
The YOLO algorithm can find nearby things like other cars, people, and parking signals in driverless vehicles. Since no human driver is operating the automobile, object, and Object detection solutions are done in autonomous vehicles to prevent collisions.
- Wildlife:
This method finds different kinds of wildlife in forests. Journalists and wildlife rangers utilize this form of detection to locate animals in still photos and films, both recorded and live. Among the animals seen are giraffes, bears, and elephants.
- Security:
YOLO can also be employed in security systems to impose security in a location. For example, assume that a particular place has security restrictions prohibiting individuals from entering. The YOLO algorithm will identify anyone who enters the restricted area, prompting the security staff to take additional action.
Differences between YOLO, YOLOv2, YOLO9000, YOLOv3, YOLOv4, YOLOR, YOLOX, YOLOv5, YOLOv6, and YOLOv7
With numerous iterations since its initial release in 2015, YOLO has seen significant development. We will learn about the variations in each of these versions in this section.
YOLO or YOLOv1
YOLO was initially created to address the issue of how to recognize items rapidly and effectively. It needs help to identify tiny images inside a group of photographs, like a person in a crowd or standing in front of a stadium. This first iteration of YOLO also has other drawbacks.
YOLOv2
To make the YOLO model stronger, faster, and better, YOLOv2 was developed. It employs a novel architecture called Darknet-19, batch normalization, inputs with better resolution, convolution layers with anchors, dimensionality clustering, and (5) fine-grained features.
YOLOv3
The YOLOv2 neural network has seen a gradual improvement. This 106-node neural network includes residual blocks and upsampling networks. Independent logistic classifiers have been added to precisely forecast the bounding boxes’ class. This method enables more useful data for a higher-quality final image.
YOLOv4
It is optimized for parallel computations and has been created primarily for use in production systems. The network’s CSPDarknet53, which has 29 convolutional layers, three filters, and over 27.6 million parameters, serves as the design framework.
For better object recognition, this architecture adds the following data to YOLOv3:
- The Spatial Pyramid Pooling (SPP) block separates the most important context elements, considerably expands the receptive field, and does not slow down the network.
- For parameter aggregation from various detection levels, YOLOv4 uses PANet instead of the Feature Pyramid Network (FPN) utilized in YOLOv3.
- Data augmentation combines a self-adversarial training method with the mosaic technique, which merges four training images.
- Use evolutionary algorithms to select the best hyperparameters.
YOLOR
YOLOR is built on a unified network, which combines explicit and implicit knowledge techniques, as a Unified Network for Multiple Tasks.
Learning that is explicit is regular or aware learning. Contrarily, implicit learning is done without awareness (from experience).
By combining these two techniques, YOLOR can build a more reliable architecture based on three processes: Feature alignment, object detection prediction alignment, and multitask learning canonical representation are listed in that order.
1- Alignment of predictions
This method increases the precision by roughly 0.5% by adding an implicit representation to each feature pyramid network’s (FPN) feature map.
2 Object detection prediction improvement
The model predictions are improved by incorporating implicit representation into the network’s output layers.
3- Canonical representation for learning several tasks
When multi-task training, the loss function shared by all the charges must be optimized jointly. Incorporating the canonical representation during the model training can lessen this process’s potential impact on the model’s overall performance.
The following graph shows that YOLOR outperformed other models regarding state-of-the-art inference speed on the MS COCO data.
YOLOX – Exceeding the YOLO Series in 2021 with YOLOX
Darknet-53 is the foundation of YOLOX, a modified version of YOLOv3. It employs a decoupled head, separating classification and localization operations. The author introduced SimOTA as an alternative to the intersection of union (IoU) method for label assignment.
YOLOv5
The YOLO operating system’s fifth and final edition, YOLOv5, is the first to be implemented in Pytorch rather than Darknet. It was made available by Glenn Jocher in June 2020, and its architecture is based on CSPDarknet53.
Without significantly affecting the map, the new architecture decreases the number of layers and parameters while increasing forward and reverse speed.
YOLOv6
The YOLOv6 (MT-YOLOv6) framework, which is dedicated to industrial applications and has a hardware-friendly, effective design and high level of performance, was published by Chinese e-commerce business Meituan.
This new version, written in Pytorch and not a part of the official YOLO, was given the name YOLOv6 because its core was modeled after the one-stage YOLO design.
Three critical upgrades to the prior YOLOv5 were made with YOLOv6: a hardware-friendly backbone and neck design, a productive decoupled head, and a more powerful training method.
YOLOv7 was published in the newspaper Trained bag-of-freebies in July 2022, setting a new standard for real-time object detectors. This version is a substantial advancement in object detection, outperforming all other versions in accuracy and speed.
A significant update has been made to YOLOv7’s (1) architecture and (2) Trainable bag-of-freebies level:
1. Architectural Level
The Extended Efficient Layer Aggregation Network (E-ELAN), which enables the model to learn more varied features for improved learning, was integrated into YOLOv7 to reform its architecture.
Furthermore, YOLOv7 grows its design by joining the architectures of the models from which it is descended, including YOLOv4, Scaled YOLOv4, and YOLO-R. As a result, the model can adapt to varying inference speeds.
2. Trainable bag-of-freebies
Bag-of-freebies is a concept used to describe ways to boost model accuracy without raising training costs, and it explains how YOLOv7 improved both infer speed and detection rate.
Conclusion:
The development of the YOLO object identification method transformed the study of object recognition in computer vision. Since it was first presented in 2015, YOLO has greatly developed, having more than five versions (3 official) and being quoted more than 16000 times. Especially for autonomous driving, vehicle identification, and intelligent video analytics, YOLO has a broad range of applicability and hundreds of use cases.

Dawood is a digital marketing pro and AI/ML enthusiast. His blogs on Folio3 AI are a blend of marketing and tech brilliance. Dawood’s knack for making AI engaging for users sets his content apart, offering a unique and insightful take on the dynamic intersection of marketing and cutting-edge technology.






