


The problem
As computer vision techniques evolve and enhance, they create room for adoption opportunities. Recently, I happened to come across one such opportunity where a pen and paper solution was being used to record the attendance of employees. This, as anybody can tell, was not only an outdated solution but also an overhead. One should certainly not be doing this living in the digital century.
Solution
Any how, one way to solve this problem was using a Computer Vision-Based Attendance System, where people would have their photos taken at the entry whenever a face is detected. These images would then be sent to a processing unit that matches the face with the employee dataset and records the attendance of the respective person.
Overview
A birds eye view of the solution looks something like below.
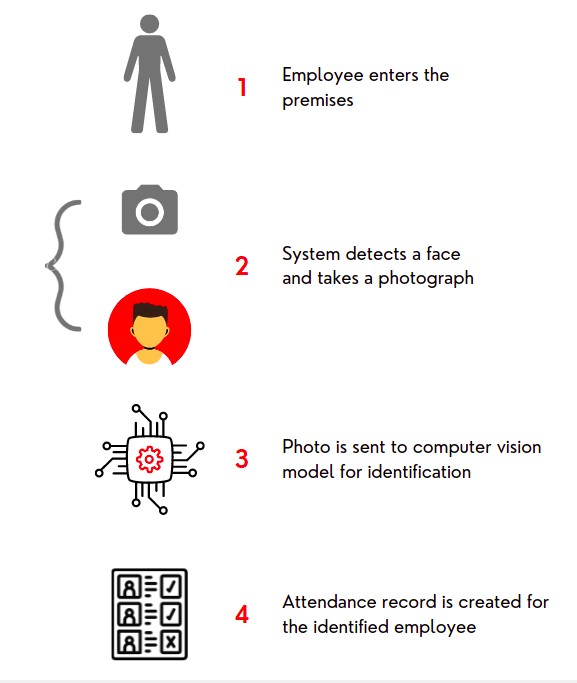
Details
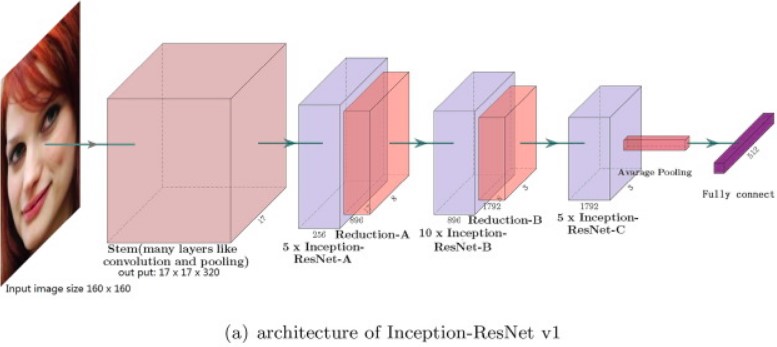
This is essentially a two-part solution where one component of the system is responsible for face detection and the other for identification/classification. For face detection, a Multi-Task Convolutional Neural Network (MTCNN) is used whereas an Inception Resnet is used for classification.
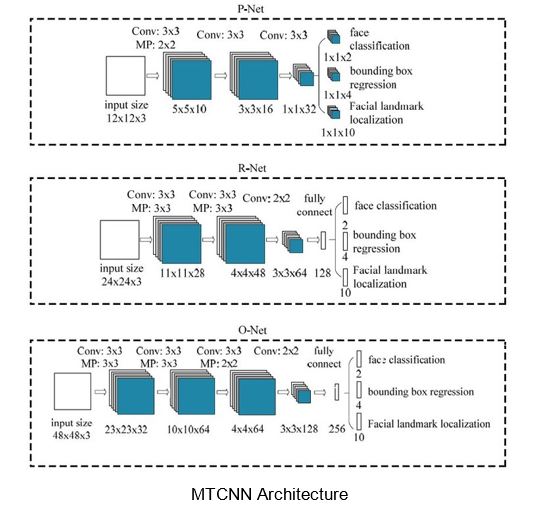
MTCNNs, as the name suggests are used for multi-task problems which in our case are faces and facial features. Fortunately for us, an MTCNN based facial detection model and a pre-trained Inception Resnet classifier were already set up by Harbman and made publicly accessible on his Github. All we needed to do was re-train the model on employees’ faces, which was not a difficult task as Habrman provided clear instructions in his repo on how to do that.
Some changes were made to the detection and reporting script. These include a threshold that defines how many successful detection frames are needed to successfully classify the person, a check that prohibits re-detection of a person whose attendance has already been marked, as well as a custom view that displays the photo of the person being identified along with the names of those who have been previously identified and marked.
Explore more about Face Recognition System in Action
Final Words
The solution performed reasonably well, as it was confidently able to tell different people apart with an average confidence of around 80%. A sample from a model trained on 4 faces is attached, demonstrating the effectiveness of this Computer Vision-Based Attendance System in accurately recognizing individuals.






