

Introduction:
Incorporating speech recognition technology into today’s digital landscape applications has become increasingly important. One powerful tool for achieving this is the Google Speech-to-Text API. This robust API allows developers to integrate accurate and real-time speech recognition capabilities into their applications.
Google Speech-to-Text API provides a reliable solution, whether it’s for transcription services, voice-controlled applications, or language processing tasks.
By leveraging advanced machine learning algorithms, developers can harness the power of this API to convert spoken language into written text with remarkable accuracy. In this article, we will explore the steps involved in Incorporating Google’s Speech-to-Text API into your apps, opening up a world of possibilities for enhanced user experiences.
What Is Google Speech-to-Text API
Google Speech-to-Text API is a powerful tool that enables developers to integrate speech recognition capabilities into their applications. This API offers accurate and real-time transcription services, making it ideal for various applications such as transcription services, voice-controlled applications, and language processing tasks.
At its core, the Google Voice-to-text API integration utilizes advanced machine learning algorithms to convert spoken language into written text. It employs Automatic Speech Recognition (ASR) API technology, trained on vast multilingual and multitask data to achieve high accuracy and robust performance.
The underlying technology behind the API leverages deep neural networks capable of understanding and transcribing spoken language with impressive precision.
One of the significant features of the Google Speech-to-Text API is its support for real-time streaming transcription. This means that developers can receive transcriptions of spoken words in near real-time as the user speaks, making it suitable for applications that require immediate feedback or live transcription services.
Furthermore, the API supports various audio formats, including popular formats like WAV, FLAC, and MP3. This flexibility allows developers to process audio from various sources, such as recorded files or live audio streams.
Integrating the Google Speech-to-Text API into applications is relatively straightforward. It involves sending audio data to the API in real-time or as a file and receiving the transcribed text as the output. The API provides comprehensive documentation and client libraries in various programming languages, making it easier for developers to incorporate this powerful speech recognition functionality into their applications.

Prerequisites for Integration
To integrate the Google Speech-to-Text API into your applications, there are a few requirements and prerequisites to remember. First, you will need a Google Cloud Platform (GCP) account, as the API is part of the services of the Google Cloud Speech-to-Text API integration. You can sign up for a GCP account and create a project to access the necessary credentials.
Next, you must enable the Google Speech-to-Text API for your project. This can be done through the GCP Console by navigating to the API Library and enabling the API.
To make API requests, you will need to authenticate your application. This can be done by obtaining an API key or setting up service account credentials, depending on your specific use case.
Regarding software, you will need a programming language of your choice and the corresponding client library or SDK for the Google Speech-to-Text API. Google provides client libraries in various languages, such as Python, Java, and Node.js, which can simplify the integration process.
Additionally, you will need audio data in a supported format, such as WAV, FLAC, or MP3, to send to the API for transcription.
By meeting these requirements and following the necessary steps, you can successfully integrate the Google Speech-to-Text API into your applications and leverage its powerful speech recognition capabilities.
Step-by-Step Google Speech-to-Text API Integration Guide
Step 1: Setting up the Google Cloud Platform (GCP) Account:
Setting up a Google Cloud Platform (GCP) account is easy.
- Visit the GCP website, click “Get started for Free” and create or sign in with a Google account.
- Set up a project with a unique name, billing account, and location.
- Access your GCP dashboard to manage resources.
Step 2: Enabling the Google Speech-to-Text API
Enabling the Google Speech-to-Text API within your GCP project is a straightforward process.
- Begin by navigating to the GCP Console and selecting your project.
- Next, search the API Library for “Google Speech to Text API.”
- Click on the API and then select the “Enable” button to activate the API for your project.
- This action will enable you to use the API’s speech recognition capabilities in your applications.
- Once the API is enabled, you can access its documentation, manage API credentials, and explore the various features and settings available for customization.
Step 3: Obtaining API Credentials
- To obtain API credentials for the Google Speech to Text API, go to the GCP Console, select your project, and navigate to “APIs & Services” > “Credentials.”
- Create the credentials, choose the appropriate type, and provide the necessary information.
- Once created, you’ll receive credentials like an API key or service account JSON file, which authenticate your application when making API requests.
These credentials ensure security and identification during interactions with the API.
Step 4: Installing and Configuring the API Client Library
- First, ensure you have the necessary programming language and development environment installed on your machine.
- Next, visit the Google Cloud documentation and find the client library section for the Google Speech-to-Text
- Select the client library for your programming language, Python, Java, or Node.js, and follow the installation instructions.
- Once the client library is installed, you must configure it with your API credentials. This typically involves setting up the authentication method, whether using an API key or service account credentials.
- Consult the client library documentation for specific instructions on configuring the library with your chosen authentication method.
- By successfully installing and configuring the API client library, you will be ready to request the Google Speech-to-Text API from your application and utilize its powerful speech recognition capabilities.



Step 5: Making API Requests
To perform speech-to-text conversions using API requests, you can follow these steps:
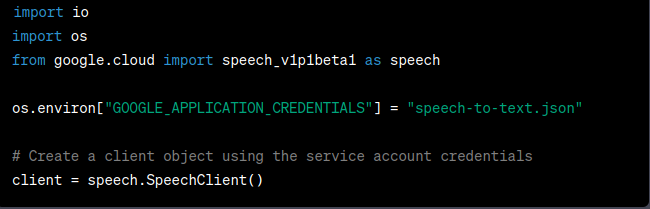
- Import Required Libraries and Set Up Authentication:
To get started, we need to import the necessary libraries: io, os, and the speech module from the Google Cloud Speech-to-Text client library.
Additionally, we set the environment variable GOOGLE_APPLICATION_CREDENTIALS to point to our service account key file (e.g., “speech-to-text.json”) for authentication.
Handling API Responses upon receiving the API response, we extract the transcribed text from the JSON response. The API typically provides a list of alternative transcriptions, but for simplicity, we retrieve the first one.
- Defining the Transcription Function:
Next, we define a Python function named transcribe_audio, which takes two parameters: file_path (the path to the audio file) and duration_seconds (the desired duration to transcribe).Inside the function, we read the audio file and create a RecognitionAudio We also set up the recognition configuration, including the audio encoding, sample rate, and language code.
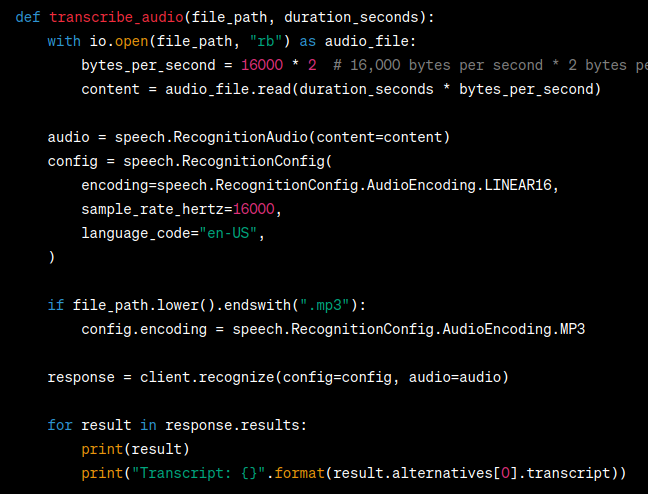
- Making API Requests:
In this step, we achieve the goal of performing speech-to-text conversions through API requests to the Google Cloud Speech-to-Text service. The transcribe_audio function acts as our interface for sending the API request and obtaining transcriptions.

- Handling API Responses:
Upon receiving the API response, we extract the transcribed text from the JSON response. The API typically provides a list of alternative transcriptions, but for simplicity, we retrieve the first one.

The Google Cloud Speech-to-Text API streamlines the process of converting spoken language into written text, providing developers with powerful speech recognition capabilities for various applications.
Handling API Responses and Advanced Features
When handling API responses, it’s essential to interpret and handle them effectively. Here are some key considerations:
- Response interpretation:
Parse the response to extract relevant data based on the API’s documentation. Respond to the response format (e.g., JSON) and access the desired information accordingly.
- Error handling:
Check the response status code to determine if the request was successful (e.g., 200 for success). Handle different status codes appropriately, such as retrying failed requests, logging errors, or notifying users.
- Advanced features and customization:
APIs often offer advanced features and customization options. These can include language or voice selection, punctuation control, speaker diarization, or timestamping for each word. Consult the API documentation to explore and implement options based on your requirements.
- Rate limiting and quotas:
APIs may have rate limits or quotas to prevent abuse. Monitor response headers for rate limit information and handle rate limit exceeded errors by implementing backoff strategies or considering subscription plans with higher limits.
- Pagination and data retrieval:
Pagination techniques such as limit-offset or cursor-based pagination might be provided for APIs returning large result sets. Understand the pagination approach and implement logic to retrieve all the desired data.
Remember to refer to the API documentation for specific details on interpreting responses, handling errors, and leveraging advanced features and customization options offered by the API provider.
Best Practices and Tips for Google Speech-to-text API Integration
To optimize the integration process and efficiently use an API, follow these best practices:
- Thoroughly understand the API documentation to grasp its capabilities and limitations.
- Implement effective error handling, including logging errors and handling rate limits.
- Utilize caching and batching to minimize unnecessary API calls and reduce latency.
- Monitor API usage and manage quotas to avoid exceeding limits.
- Account for network failures by implementing retry strategies with backoff.
- Minimize data transfer by requesting and transmitting only necessary information.
- Secure sensitive data through encryption and secure communication protocols.
- Stay updated with API changes to plan for migration or adaptation.
By following these practices, you can optimize integration, enhance performance, and ensure reliable application integration.
Conclusion:
In conclusion, integrating the Google Speech-to-Text API can bring powerful speech recognition capabilities to your applications. Throughout this blog post, we have covered several key points:
- Understanding the Google Speech-to-Text API: We discussed how this API leverages machine learning to convert spoken language into written text, opening up a wide range of possibilities for voice-based applications.
- Enabling the API in your GCP project: We provided step-by-step instructions on enabling the Google Speech to Text API in your Google Cloud Platform project, ensuring you have access and credentials.
- Usage limits and pricing considerations: We highlighted the API has usage limits and provided guidance on checking the pricing details to understand any associated costs.
By integrating the Google Speech-to-Text API, you can enhance your applications with speech recognition capabilities, enabling voice commands, transcription services, voice assistants, and more.
The API offers customization options, advanced features, and reliable performance backed by Google’s expertise in machine learning.
The moment has come to start developing cutting-edge applications that can comprehend and process spoken language by utilizing the capabilities of the Google Speech-to-Text API. Explore the countless possibilities of Google speech recognition API integration that might guide and can bring to your projects by getting started right away.
FAQs:
What is Google Speech-to-Text API, and how does it work?
Google Speech-to-Text API is a service that converts spoken language into written text. It utilizes advanced machine learning algorithms to analyze audio and transcribe it into text.
How do I enable the Google Speech-to-Text API in my GCP project?
To enable the Google Speech-to-Text API, navigate to the Google Cloud Console, select your project, go to the API Library, search for “Speech-to-Text API,” and enable it. You will also need to set up authentication and obtain API credentials.
Are there any usage limits or pricing considerations for using the Google Speech-to-Text API?
Yes, the Google Speech-to-Text API has usage limits and pricing considerations. The details can be found on the Google Cloud pricing page, where you can review the pricing tiers, quotas, and any additional charges for usage beyond the free tier.






