


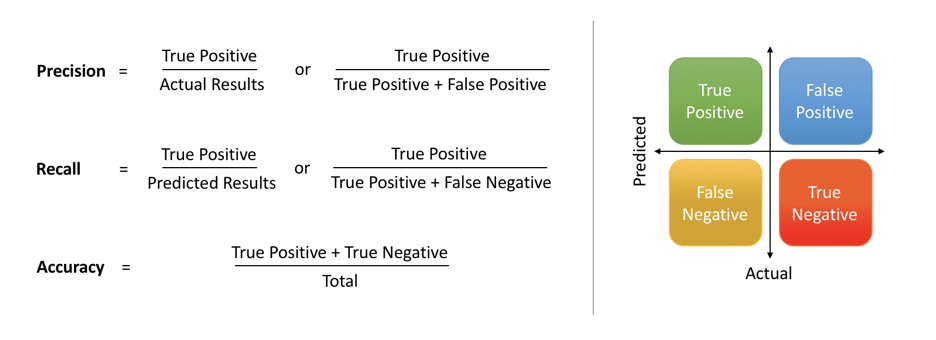
Precision and Recall are commonly cited as challenging machine learning and data science concepts. Once you understand the fundamental meaning of each term, it will become easier to grasp the difference between those two metrics.
Some experts provide incomplete explanations that further confuse new users. Understanding precision and recall clearly is important for effectively interpreting and evaluating machine learning models.
Machine learning models, ranging from medical diagnosis to cybercrime filtering, have become part of our daily lives. But how do you really measure the effectiveness of a model, then?
Accuracy, a familiar metric, can be deceptive. Imagine a cancer diagnosis system boasting 99% accuracy. While impressive, it could still miss 1% of tumors, with potentially disastrous consequences. This is where precision & recall step in, offering a more nuanced perspective on model performance.
In this blog, we will understand the difference between precision vs. recall and how to use them.
But before diving into the definition, let’s examine the spam filter example to understand precision & recall.

Understanding Precision and Recall with a Spam Filter Example
Imagine you’re training a spam filter to identify unwanted emails in your inbox. Let’s see how precision and recall help evaluate its performance:
Precision
- Definition: Precision focuses on the accuracy of your filter’s positive predictions (emails flagged as spam). It essentially asks: “Out of all the emails the filter classified as spam, how many were actually spam?”
- Formula: Precision = (True Positives) / (True Positives + False Positives)
- TP (True Positives): Emails correctly identified as spam.
- FP (False Positives): Important emails mistakenly flagged as spam.
- Example: Your filter identifies 30 emails as spam. Upon checking, 25 are true spam (TP), while 5 are important emails flagged incorrectly (FP).
- Using the formula: Precision = 25 / (25 + 5) = 0.83 (or 83%)
- Interpretation: The filter has a precision of 83%. So, out of every 10 emails it flags as spam, 8 are actual spam, and 2 are important emails it flagged incorrectly.
Recall
- Definition: Recall emphasizes the completeness of your filter’s positive predictions. It asks: “Out of all the spam emails in your inbox, how many did the filter correctly classify as spam?”
- Recall = True Positives / (True Positives + False Negatives)
- FN (False Negatives): Spam emails the filter missed.
- Example: You have 40 spam emails in your inbox. The filter identified 30 emails as spam (from the precision example), but only 25 were true spam (TP).
- This means the filter missed 40 total spam emails – 25 identified spam emails = 15 spam emails (FN).
- Using the formula: Recall = 25 / (25 + 15) = 0.63 (or 63%)
- Interpretation: The filter captured 63% of the spam emails, missing 37% (15).
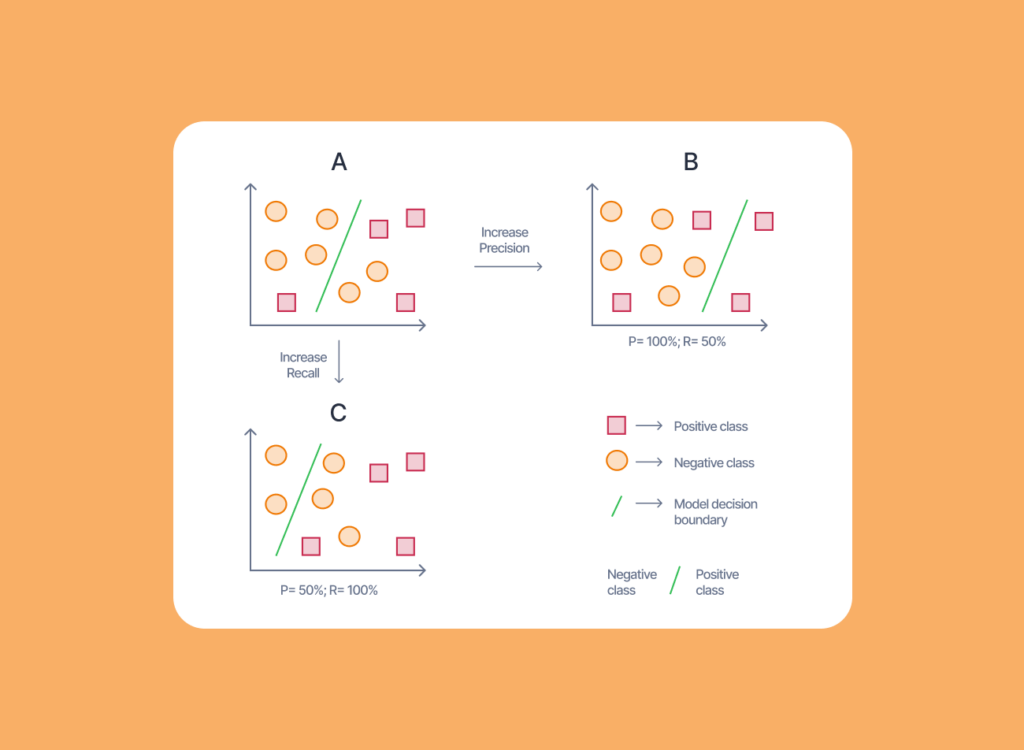
The Trade-off between Precision and Recall
This example highlights the potential trade-off between precision and recall. A higher precision (filter avoids flagging important emails) might come at the cost of lower recall (missing some spam emails).
You’ll need to decide which metric is more important for your needs. For instance, if missing important emails is a bigger concern, you might adjust the filter to prioritize higher recall, even if it means catching some non-spam emails in the process.
Why are Precision and Recall Important?
Precision and recall are paramount in machine learning tasks, especially classification because accuracy can mislead you. They’re important because of the following reasons.
1. Understanding Model Performance
- Accuracy: A single metric like accuracy simply tells you the percentage of correct predictions. However, it doesn’t reveal how the model arrived at those results. A model can achieve high accuracy by overwhelmingly predicting a single category, even if that category is incorrect in many cases.
- Precision and Recall: These metrics provide a deeper understanding by dissecting how well the model handles optimistic predictions (classifications). Precision tells you how good the model is at avoiding mistakes (e.g., identifying real cats and not mistaking dogs for cats). Conversely, Recall focuses on how well the model captures all the relevant cases (finding all the actual cats in your dataset).
2. Making Informed Decisions for Specific Tasks
The importance of precision versus recall depends on the specific problem you’re tackling. Here are some scenarios where each metric takes center stage.
- High Precision is Critical When False Positives are Costly: Imagine a medical diagnosis system. A false positive for a serious disease (indicating a disease when there’s none) could have severe consequences. Minimizing mistakes is crucial here, making precision the more important metric.
- High Recall is Essential When Missing True Positives is Unacceptable: Consider a system filtering spam emails. Missing an important email (low recall) would be undesirable, even if it means letting through some spam (lower precision). Here, catching all the relevant emails (true positives) is key, making recall the more important metric.
3. Optimizing for Different Needs
Precision and recall often have a trade-off. Focusing on maximizing one might negatively impact the other. Understanding both metrics allows you to find a balance that best suits your requirements. For instance, you might prioritize high precision for a medical diagnosis system while aiming for a good balance between precision and recall for a spam filter.
4. Foundation for Other Metrics
Precision and recall are the building blocks for other valuable metrics like F1 score and ROC-AUC curve. These metrics provide even deeper insights into model performance, considering factors like class imbalance and exploring the trade-off between precision and recall across different thresholds.
Precision and recall empower you to go beyond a surface-level understanding of accuracy and make informed decisions about your machine-learning models for various classification tasks. They provide the tools to assess how well your model avoids mistakes, captures all relevant cases, and ultimately achieves the desired outcome for your specific application.
Other Metrics Related to Precision and Recall
In addition to precision and recall, other metrics are commonly used to evaluate a machine-learning model’s performance. These include.
- Accuracy: measures the overall correctness of predictions made by the model.
- F1 score: combines precision and recall into one metric, considering false positives and false negatives.
- Specificity: measures the proportion of correctly identified negative cases out of all actual negative cases in the dataset.
- FPR (False Positive Rate): measures the proportion of incorrectly identified positive cases out of all negative cases in the dataset.
Balancing Precision and Recall
As mentioned earlier, precision and recall are often inversely related. This means that improving one metric may result in a decrease in the other. Therefore, machine learning practitioners must find a balance between these metrics depending on their specific task or application.
For example, in a medical diagnosis setting, it may be more important to have high recall (to ensure that all positive cases are correctly identified), even if it means sacrificing some precision. On the other hand, in a spam email detection task, precision may be more important to avoid mistakenly labeling legitimate emails as spam.
Choosing the Right Metric
Ultimately, the choice of which metric to focus on (precision or recall) depends on the specific task and its requirements. Machine learning practitioners should carefully consider the trade-offs between these metrics and choose the one that aligns with their goals.
1. Consider the Cost of Errors
- High Cost of False Positives: If false positives (mistaking negatives for positives) have severe consequences, prioritize high precision. Imagine a medical diagnosis system—a false positive for a critical disease could be disastrous. Minimizing mistakes is crucial here.
- High Cost of False Negatives: If missing true positives (failing to identify actual positives) is unacceptable, prioritize high recall. Think of a system filtering financial fraud – missing a fraudulent transaction (low recall) could be detrimental, even if it means letting through some legitimate transactions (lower precision).
2. Analyze the Data Distribution
- Balanced Data: If your dataset has a roughly even distribution of positive and negative classes, accuracy, precision, and recall might all be relevant metrics. You can aim for a good balance between them.
- Imbalanced Data: Accuracy can be misleading when one class is significantly rarer than the other. Here, precision and recall for the minority class become more important. Techniques like oversampling or under sampling can help balance the data and improve overall performance.
There’s no single “best” metric for all classification tasks. By understanding the cost of errors, data distribution, and the trade-off between precision and recall, you can select the most appropriate metric (or a combination of metrics) to effectively evaluate your model’s performance. Remember, the goal is to choose a metric that aligns with the desired outcome for your specific task.
Improving Precision and Recall
In addition to understanding and balancing precision and recall, there are also various techniques that can be used to improve these metrics in machine learning models. Some of these techniques include:
- Data preprocessing: cleaning and preparing the data before training the model can help reduce noise and improve accuracy.
- Feature selection: selecting the most relevant features for training the model can improve its performance.
- Model selection: using different algorithms and models can help identify the best one for a specific task.
- Parameter tuning: adjusting specific parameters in the model can improve its performance.
- Ensemble methods: combining multiple models can lead to better predictions and higher precision/recall scores.
By implementing these techniques, machine learning practitioners can work towards improving both precision and recall in their models.
Conclusion
In conclusion, Both are important metrics in evaluating the performance of a machine-learning model. They provide different insights into the model’s accuracy and ability to identify positive cases. As with any evaluation metric, it’s essential to understand their trade-offs and choose the appropriate balance depending on the specific task or application.
Machine learning and researchers should regularly analyze and enhance these metrics in their models to achieve optimal performance. Precision and accuracy must also be considered to gain a comprehensive understanding of the model’s performance.

Dawood is a digital marketing pro and AI/ML enthusiast. His blogs on Folio3 AI are a blend of marketing and tech brilliance. Dawood’s knack for making AI engaging for users sets his content apart, offering a unique and insightful take on the dynamic intersection of marketing and cutting-edge technology.






