


Introduction:
Have you ever found yourself in a dilemma between two lunch restaurants?
How do you end up deciding on one? The weighing out of pros and cons and the series of questions you may ask yourself: Chinese or American? Fast Food or Fine Dine? Cheap or Expensive? These are the very base of a decision tree, creating a path that ultimately results in a decision. Many possible paths exist where each path is different due to each decision made.
This is how in machine learning terminology, machines decide for any certain scenario, and that is what we will be discovering in this blog post, from how they work, why they are required, and how or where to apply them. Whether you love coding or just have a curious mind, by the end of this blog you will have a solid grasp of how decision trees help machines make informed decisions.
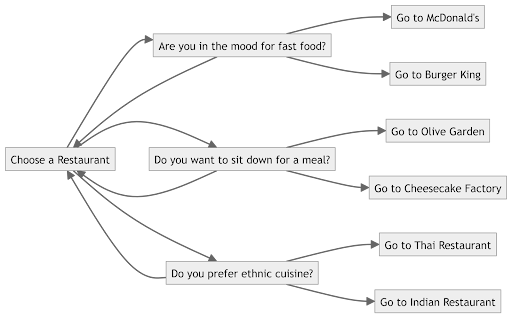

What is a Decision Tree?
It behaves exactly like a tree in structure, where each decision is a branch and all end at a decision. In machine learning a decision tree is an algorithm used for either of the two tasks, Regression, and Classification. Regression is a type of algorithm where we deal with continuous data such as Housing Prices, and Classification deals with discrete values where output is categorical. In a visual representation, the branches represent the data split and the leaves are the outcomes.
How does a Decision Tree work?
To explain how a decision tree works we can imagine a scenario such as deciding to go on a walk, you would be considering factors such as temperature, wind, rain, etc.
At the heart of a decision tree is the process of splitting down the dataset to help make decisions
1. Root Node:
We start from the root node which represents the complete dataset, this is where decision-making begins.
2. Attribute Selection:
The key to constructing a Decision Tree lies in selecting attributes that the data is split on.
Each split aims to split the data into subsets where purity is enhanced subsequently, making it easier to classify or predict an outcome.
An attribute is chosen based on its ability to maximize Information Gain for that split.
3. Information Gain:
Information Gain is a measure that shows the amount of impurity reduced by a certain attribute splitting the data.
It is measured by comparing the entropy of data before and after splitting.
let’s take our scenario here and choose a suitable attribute.
Is it raining? is a pivotal attribute when deciding to go for a walk. If this attribute decreases our entropy enough, it raises our information gain and therefore is a suitable attribute to split the data on.
4. Creating Branches:
When data is split based on an attribute, generated branches represent the different outcomes. For example, the question, Is it raining? would be answered in yes or no and a separate branch carrying subsets of the dataset corresponding to each would be created.
5. Recursive Splitting:
The process of attribute selection and splitting occurs for each branch, creating a class-biased hierarchical structure till a stopping criterion is met.
Common stopping criteria include reaching a maximum depth, having a node with pure subsets (all instances belong to the same class), or having a minimum number of instances in a node.
6. Leaf Node:
The terminal nodes of the tree, known as leaf nodes, represent the final decisions or predictions. Each leaf node corresponds to a specific outcome.
In our walking scenario, the leaf nodes would indicate the final decision: “Go for a walk” or “Do not go for a walk.”
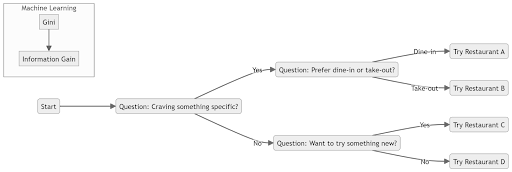
Splitting Criteria for a Decision Tree:
The splitting criteria for a decision tree is determining how to create subsets of a given dataset while maximizing the homogeneity of the data within each subset. The measure of impurities in a dataset varies on the type of problem.
- Classification: for classifying problems, Gini(measuring the probability of misclassifying a random element), Information Gain(reduction of entropy after a dataset is split based on an attribute), or Entropy-based(amount of information needed to classify a member of the dataset) splitting is used.
- Regression: for regression tasks, mean squared error (MSE) or minimizing variance is used where the goal is to create splits that reduce the difference between output and predicted values.
Two popular methods are:
Information Gain and Entropy:
Entropy is a measure of disorder or uncertainty. In the context of decision trees, it quantifies the impurity of a dataset. The formula for entropy is:
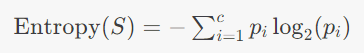
where :
- S is the dataset.
- c is the number of classes.
- pi is the proportion of instances in class i.
Information gain is the reduction in entropy due to a split on a particular attribute. It’s calculated as:
where:
![]()
- 𝑆 is the dataset.
- 𝐴 is the attribute.
- 𝑣 are the values of attribute 𝐴
- 𝑆𝑣 is the subset of 𝑆 where attribute 𝐴 has value 𝑣
Example: If we’re classifying fruits and asking “Is it red?” reduces entropy by half, that’s a good question with high information gain.
Gini Impurity:
Gini impurity measures the probability of incorrectly classifying a randomly chosen element in the dataset if it were randomly labeled according to the distribution of labels in the subset. The formula for Gini impurity is:
where:
![]()
- 𝑆 is the dataset.
- 𝑐 is the number of classes.
- 𝑝𝑖 is the proportion of instances in class 𝑖.
Example: If asking “Is it an apple?” results in most answers being yes, that’s low Gini impurity.
Pruning a Decision Tree:
The word pruning may ring a bell if you are familiar with gardening. It refers to the act of selectively cutting down individual branches to improve the structure of the tree.
In decision trees, it is a method that helps avoid overfitting which is when a model trains too well where it also learns noise and other such outliers which decrease its performance on new data.
Pruning works the same way in machine learning by removing unwanted or unnecessary branches and simplifying the tree. There are two types of pruning:
- Pre-Pruning: Stopping the tree-building process before it becomes too complex.
- Post-Pruning: Allowing the tree-building process to complete and then pruning(removing) the branches contributing to overfitting.
Decision Trees Using Python:
We use two well-known implementations for both problem types to implement Decision Trees in Python.
Python Decision Tree Classifier:
In Python “DecissionTreeClassifier” is a popular implementation for classifying tasks using decision trees, the “sklearn.tree” module from the SciKit-Learn library can be used.
Here is a basic code example of how to implement it in Python
(I would use a code box here)
“
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# Load a dataset
iris = load_iris()
X = iris.data
y = iris.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create a DecisionTreeClassifier
clf = DecisionTreeClassifier(criterion=’gini’, max_depth=3)
# Train the classifier
clf.fit(X_train, y_train)
# Make predictions
predictions = clf.predict(X_test)
# Evaluate the classifier
accuracy = clf.score(X_test, y_test)
print(f’Accuracy: {accuracy}’)
“
In the example code above, criterion = ‘gini’ shows that Gini Impurity is being used as the splitting criterion, and max_depth=3 limits the depth of the tree to prevent overfitting.
Python Decision Tree Regressor:
For regression tasks, the “DecissionTreeRegressor” is also a part of the “sklearn.tree” module and works similarly to the “DecissionTreeClassifier” but is used to predict continuous values instead.
Here is an example Python implementation:
“
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
# Load a dataset
housing = fetch_california_housing()
X = housing.data
y = housing.target
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create a DecisionTreeRegressor
regressor = DecisionTreeRegressor(max_depth=3)
# Train the regressor
regressor.fit(X_train, y_train)
# Make predictions
predictions = regressor.predict(X_test)
# Evaluate the regressor
mse = mean_squared_error(y_test, predictions)
print(f’Mean Squared Error: {mse}’)
“
Real-Life Use Cases Using Decision Trees:
Decision trees are versatile and can be used in a wide range of real-life problems, here are some common use cases:
- Banking: Decision trees can be used to predict loan defaults based on customer data, helping banks to manage risk.
- Healthcare: They can assist in diagnosing diseases by analyzing symptoms and patient history, aiding doctors in making informed decisions.
- Marketing: Decision trees can segment customers and predict their purchasing behavior, enabling targeted marketing campaigns.
- E-commerce: They can be used for product recommendations by predicting what items a user might be interested in based on their browsing and purchase history.
- Fraud Detection: Decision trees can identify patterns that indicate fraudulent transactions in financial data.
- Weather Forecasting: They can predict weather patterns by analyzing historical data and various meteorological factors.
- Stock Market Analysis: Based on historical data, decision trees can help predict stock prices and market trends.
Conclusion
Decision trees are more than just a tool; they’re a way to make sense of the world through data. They help us ask the right questions and make smart decisions. Whether you’re a data scientist or just curious, understanding decision trees can open up a world of possibilities. If used correctly, it is a valuable tool in machine learning that can solve various problems. Try implementing them on different datasets and see if it works best for you. Understanding their inner workings and how to implement them in Python can greatly amend your abilities as a data scientist.
Ready to Explore Decision Trees?
Are you eager to delve into the realm of decision trees using Python? Start making data-driven decisions that are both smart and savvy.
At Folio3 AI, a software company renowned for its expertise in AI, computer vision, and machine learning, we specialize in helping clients harness the potential of advanced machine-learning techniques such as decision trees.
Our team at Folio3 AI is adept at leveraging these technologies to enhance various business processes. Whether you’re looking to refine customer segmentation, bolster your fraud detection mechanisms, or optimize product recommendations, our capabilities are designed to unlock the full potential of your data. We believe in the power of data to drive smarter, more impactful business outcomes and favorable solutions for our clients.

Dawood is a digital marketing pro and AI/ML enthusiast. His blogs on Folio3 AI are a blend of marketing and tech brilliance. Dawood’s knack for making AI engaging for users sets his content apart, offering a unique and insightful take on the dynamic intersection of marketing and cutting-edge technology.






