


Machine learning is a part of computer science that allows computers to learn on their own without being directly told what to do. There are two main types: supervised learning and unsupervised learning. We thought of writing this blog to help you understand supervised machine learning and will cover unsupervised in our upcoming blogs.
So, if you are into machine learning, this blog about supervised machine learning will be helpful to read.
Supervised Machine Learning Explained
Supervised machine learning is a type of machine learning where machines are trained using well–“labeled” data. This means that the input data is already tagged with the correct output. Using this data, the machine learns to make accurate predictions.
In supervised learning, the labeled data acts as a guide, similar to how a teacher helps a student learn. The process involves providing both the input data and the corresponding correct output to the machine learning model. The goal of the supervised learning algorithm is to discover a function that correctly maps the input variable (x) to the output variable (y).
There are various terms that you may encounter when hearing about supervised machine learning solutions.
- Labels and Features: In supervised learning, labels represent the output or prediction target, while features are the input variables used to make the prediction.
- Training, Validation, and Test Sets: The dataset is split into three parts. The training set is used to train the model, the validation set to tune the parameters and prevent overfitting, and the test set to evaluate the model’s performance.
- Model Evaluation Metrics: Accuracy, precision, recall, and F1 score are common metrics used to assess the performance of a model, depending on the nature of the problem being solved.

Examples Of Supervised Machine Learning
Supervised machine learning is used in many everyday technologies. For example, devices like Alexa and Google Home turn our speech into text, and facial recognition on our phones makes them more secure. Google Maps uses it to predict traffic and find the best routes.
Chatbots in fields like banking and healthcare help answer customer questions quickly online. Google Translate breaks down language barriers by translating text.
In banking, it helps predict who might not pay back a loan. It can also organize messy data into a clear format for easier understanding. In the stock market, it finds good times to buy or sell.
Self-driving cars use it to move around safely without a person driving. It makes ads on the internet more personal, based on what you’ve looked at before. Security cameras can spot and report anything out of the ordinary. Prices in apps like Uber can change based on how many people need a ride, thanks to machine learning.
All is done through machine learning, particularly supervised machine learning.
Common Algorithms in Supervised Learning
- Decision trees and random forests are powerful for classification and regression tasks and are capable of handling complex decision-making processes.
- Support Vector Machines (SVM) excel in classification problems, especially in high-dimensional spaces.
- Linear Regression is used for predicting continuous values, employing a linear approach to model the relationship between input features and the target variable.
- K-Nearest Neighbors (KNN) is a simple, yet effective method for both classification and regression, based on finding the closest data points in the training dataset.
Types Of Supervised Machine Learning
1. Classification
Classification is a type of supervised machine learning where the computer learns from past data to guess what will happen next. For example, a bank could look at what you’ve done with your money before, like your credit history and loans, to figure out if you might not pay back a loan.
In this situation, the stuff about your money history and loans are called Features. Whether you didn’t pay back a loan before is the Target, and it’s shown as a simple yes or no, true or false, or 1 or 0.
Classification algorithms make these guesses. If there are only two choices (like yes or no, or true or false), it’s called Binary Classification. If there are more choices, it’s called Multiclass Classification.
Several machine learning algorithms can be used for classification. These algorithms help in making accurate predictions based on the data provided., including:
- Logistic Regression
- Decision Tree Classifier
- K Nearest Neighbor Classifier
- Random Forest Classifier
- Neural Networks
2. Regression
Regression is a basic kind of supervised machine learning. In this method, algorithms learn from data that already has answers to predict numbers like sales, salaries, body weight, or temperatures.
This is different from classification tasks, where the goal is to pick the right category for new data. With regression, the algorithm needs to figure out the complex connections between different factors and the outcome we want to guess.
Let’s say we have a simple list of cars, including details like how big the engine is, how many miles it can go on a gallon of gas, how old it is, and how far it’s been driven. This list also shows how much each car is worth right now.
A regression algorithm looks at this info to understand how these details—like engine size, gas mileage, age, and distance driven—affect a car’s price. By spotting patterns and connections in the list, the algorithm can guess the prices of other cars not in the list, based on their details.
This skill to predict new information from known data is super useful in many areas, like business or science.
Many machine learning algorithms can be used for regression tasks, These algorithms help in predicting continuous values based on the provided data. including:
- Linear Regression
- Decision Tree Regressor
- K Nearest Neighbor Regressor
- Random Forest Regressor
- Neural Networks
Steps Involved In Supervised Machine Learning
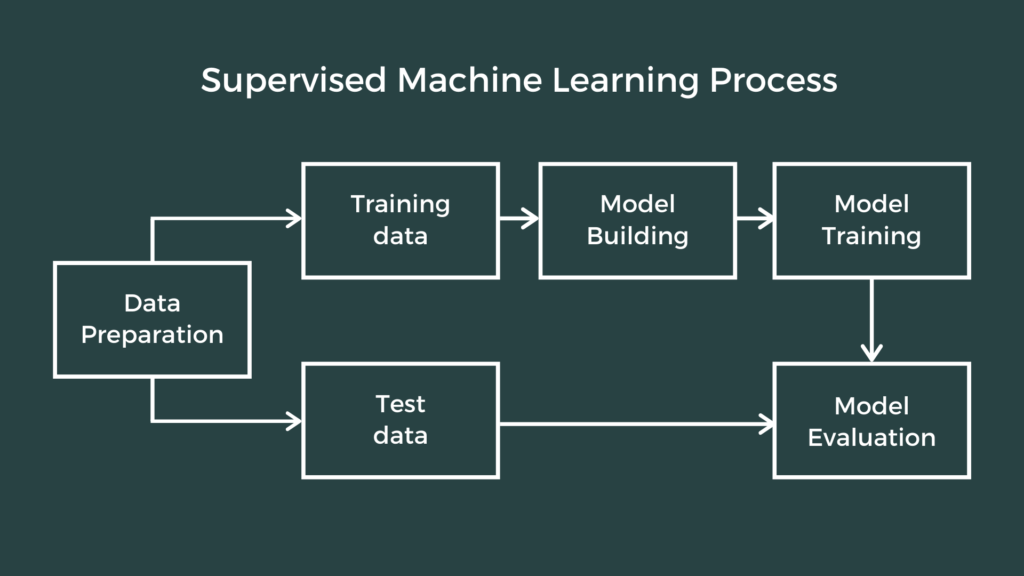
1. Determine the Type of Training Dataset
First, figure out the exact problem you want to tackle, like if you’re dealing with classifying things (like spotting spam) or predicting values (like house prices). Get to know the kind of data you need, whether it’s numbers, categories, or a mix. It’s super important that the data fits the problem well and truly shows the different situations your model could face.
2. Collect/Gather the Labelled Training Data
Collect data that are marked with an outcome or category. Make sure you gather data consistently and reliably to keep it high-quality. It’s important to clean up the data, fixing any missing pieces, odd values, or mistakes. You might also need to adjust the data, like making everything a similar size or scale, to get it ready for analysis.
3. Split the Training Dataset
Split the dataset into three simple parts: the training set, the validation set, and the test set. Usually, the training set uses 70-80% of the data, while both the validation and test sets each take 10-15%.
This way, we can train, check, and test the model properly. It’s key to keep the same mix of data in each part to prevent any unfairness that might mess with how well the model works.
4. Determine the Input Features
Find the most important parts of the training dataset that help predict what you want. These parts should give enough info for the model to understand patterns and connections.
Picking these parts might need expert knowledge, looking at data in simple ways, and using methods to figure out which parts are really important. This makes sure the model uses the best predictors to learn.
5. Choose a Suitable Algorithm
Choose the right method to create your model by looking at what problem you’re solving and what your data is like. Popular methods are things like support vector machines (SVM), decision trees, random forests, and neural networks. Your choice might also be influenced by how big your data is, how complicated the problem is, and what kind of computer power you have accessible.
6. Train the Model
Run the selected algorithm on the training dataset to create the model. In this step, the model gets better at making predictions by changing its settings based on what it learns from the training data.
We also use validation sets to adjust the model’s complex settings and prevent it from making overly specific guesses. This helps in making sure the model works well and fairly during training.
7. Evaluate the Model
Check how right the model is by using the test set, which it didn’t see while learning. We see how good the model is by looking at how well it guesses the results for the test data.
We often use simple measures like accuracy, precision, recall, and F1 score to understand how effective the model is. If the model does well on the test set, it means it has learned properly and can apply what it knows to new data it hasn’t seen before.
Applications Of Supervised Machine Learning
- Spam Filtering: Supervised learning algorithms can learn to spot and sort out spam emails by looking at what they’re about, making it easier for people to keep their inboxes free from unwanted emails.
- Image Classification: This kind of learning can sort pictures into groups like animals, objects, or places on its own. It’s handy for things like finding pictures, checking content, and suggesting products with images.
- Medical Diagnosis: Supervised learning can assist doctors by examining patient information like medical pictures, test outcomes, and past health records. It can spot trends that point to certain illnesses, helping doctors diagnose them quicker and more precisely.
- Fraud Detection: These models can check financial transactions and find patterns that show fraud. This helps banks and other money places stop fraud and keep their customers safe.
- Natural Language Processing (NLP): Supervised learning is key for tasks related to human language. It helps machines understand and work with our language better. This includes figuring out if text has a positive or negative vibe, translating between languages, and making long texts shorter.
Pros & Cons Of Supervised Machine Learning
Supervised machine learning has its ups and downs. A big plus is its accuracy – since it learns from data that’s already been sorted and labeled, it’s good at tasks like sorting things into categories or predicting outcomes. It’s super flexible too, useful in areas like health, finance, and recognizing images.
But, it needs a lot of pre-sorted data to learn from, which can take a lot of time and money to put together. Also, there’s a chance it might get too attached to the data it was trained on, making it not so great at handling new stuff. Plus, picking the right algorithm and adjusting it just so takes a lot of know-how and power.
Final Thoughts
Supervised machine learning is a key part of machine learning where we use data that’s already marked with the right answers to teach models how to make correct guesses and sort stuff. It’s used for lots of things like stopping spam emails, recognizing what’s in pictures, figuring out health diagnoses, spotting fraud, and understanding human language.
It’s accurate and flexible, but you need a lot of data that’s already been sorted out and the know-how to pick and tweak the right methods. This can make getting your data ready and making sure your model works well for different situations a bit tricky.
Even with these hurdles, supervised learning is super useful for pushing technology forward and tackling tricky problems in the real world. Getting to grips with how it works and where it can be used can up your game in all sorts of areas.
FAQ: What Is Supervised Machine Learning? A Comprehensive Overview
1. What is supervised machine learning?
Supervised machine learning is a type of artificial intelligence where an algorithm learns from labeled training data to make predictions or decisions. The model is trained on a dataset that includes both input features and corresponding correct outputs.
2. How does supervised learning differ from unsupervised learning?
In supervised learning, the algorithm is trained using labeled data, meaning each training example is paired with an output label. In contrast, unsupervised learning involves training on data without labeled responses, and the algorithm tries to identify patterns and relationships within the data.
3. What are the main types of supervised learning tasks?
The two main types of supervised learning tasks are classification and regression. Classification involves predicting a categorical label, such as determining if an email is spam or not. Regression involves predicting a continuous value, like forecasting house prices.
4. What are some common algorithms used in supervised machine learning?
Common algorithms include Linear Regression, Logistic Regression, Decision Trees, Random Forests, Support Vector Machines (SVM), k-Nearest Neighbors (k-NN), and Neural Networks.
5. How is a supervised learning model trained?
A supervised learning model is trained by feeding it a labeled dataset where the algorithm learns the mapping from input features to the output labels. The training process involves optimizing a loss function to minimize the error between the predicted and actual outputs.
6. What is a training set and a test set?
A training set is a subset of the dataset used to train the model. A test set is a separate subset used to evaluate the performance of the trained model, ensuring it can generalize to unseen data.
7. What is overfitting in supervised learning?
Overfitting occurs when a model learns the training data too well, including noise and outliers, resulting in poor generalization to new, unseen data. It can be mitigated by techniques such as cross-validation, pruning, or regularization.
8. How can you evaluate the performance of a supervised learning model?
Performance can be evaluated using metrics such as accuracy, precision, recall, F1 score for classification tasks, and mean squared error (MSE), mean absolute error (MAE) for regression tasks. Cross-validation is also commonly used to assess model performance.
9. What are some real-world applications of supervised machine learning?
Supervised learning is used in various applications such as email spam detection, image recognition, fraud detection, customer segmentation, medical diagnosis, and predictive maintenance.
10. What are the steps involved in building a supervised learning model?
The steps include: 1. Collecting and preprocessing data. 2. Splitting the data into training and test sets. 3. Choosing a suitable algorithm. 4. Training the model on the training set. 5. Evaluating the model on the test set. 6. Fine-tuning the model parameters. 7. Deploying the model for prediction on new data.

Dawood is a digital marketing pro and AI/ML enthusiast. His blogs on Folio3 AI are a blend of marketing and tech brilliance. Dawood’s knack for making AI engaging for users sets his content apart, offering a unique and insightful take on the dynamic intersection of marketing and cutting-edge technology.






