

The state-of-the-art object detection framework YOLOv8 Architecture is distinguished by its remarkable speed-accuracy balance. You will gain a thorough understanding of its capabilities by following this guide, which will take you through its internal operations.
Object detection, or the process of locating and identifying objects in images and videos, is the main goal of computer vision.
And we have seen numerous applications, such as autonomous automobile systems and medical image processing, depend on this task. However, some of the traditional approaches often face challenges in striking a balance between speed and precision.
But in 2024, we have recent advances in deep learning which made it easier to create reliable tools with high accuracy and efficiency, such as YOLOv8 (You Only Look Once Version 8).
What Is YOLOV8
The most recent advanced object identification model in Ultralytics’ YOLO (You Only Look Once) series is called YOLOv8.
It is a strong and adaptable computer vision framework that can be applied to tasks including instance segmentation, object detection, and image classification.
Because of its quickness and precision in object detection, it is a helpful tool for numerous computer vision applications. A summary of YOLOv8 and its distinguishing features is provided here.
- Object Detection Powerhouse: YOLOv8 finds and recognizes objects in videos and images. Bounding boxes are capable of differentiating between objects in a scene and pinpointing their exact placement.
- Speed and accuracy balance: Compared to certain object identification models that prioritize speeds over precision, YOLOv8 achieves an impressively balanced speed and accuracy balance. It is therefore appropriate for real-time applications where quick processing is essential.
- The latest version of the YOLO legacy: YOLOv8 is the most recent iteration of a popular YOLO model series, each of which builds on the advantages of its predecessor. Advanced deep learning architectures and optimization techniques are incorporated to achieve outstanding performance.
![]()
Evolution of YOLO: From YOLOv1 to YOLOv8
The YOLO (You Only Look Once) series has become synonymous with real-time object detection. The architecture has been refined over time to push the limits of speed and precision.
Here’s a glimpse into the evolution of YOLO, from its inception to the state-of-the-art yolov8 architecture,
YOLOv1 (2015)
-
- Revolutionizing Object Detection: Introduced a novel single-stage detection system, making object detection significantly faster than previous methods.
- Single Regression Approach: YOLOv1 treated object detection as a single regression problem, predicting bounding boxes and class probabilities directly from the entire image in one go.
- Accuracy Challenges: While groundbreaking for speed, YOLOv1’s accuracy initially lagged behind more complex two-stage detection models.
YOLOv2 (2016)
Addressed the accuracy limitations of YOLOv1 by introducing several improvements.
- Batch Normalization: Enhanced training stability and speed.
- Higher Resolution Feature Maps: Provided richer contextual information for better object localization.
- Anchor Boxes: Predefined boxes of various sizes and aspect ratios aided in predicting bounding boxes for different object shapes.
YOLOv3 (2018)
Further improved accuracy while maintaining real-time performance:
- Object Scale Prediction: Introduced separate predictions for object scale along with bounding box coordinates, leading to more precise localization.
- Multi-Scale Feature Extraction: Utilized features from different layers of the network to handle objects of varying sizes more effectively.
- Logits vs. Softmax: Employed a different activation function for classification, resulting in better class probability predictions.
YOLOv4 (2020)
Offered a modular design with different versions (e.g., YOLOv4-tiny, YOLOv4-CSPDarknet53) catering to a wider range of performance and resource constraints it Introduced innovations like:
- Spatial Attention Module (SAM): Focused on the most informative regions within the feature maps for improved accuracy.
- Mish Activation Function: Offered better gradients for faster training compared to traditional activation functions.
YOLOv5 (2020)
Streamlined the architecture for efficiency and ease of use and introduced innovations like:
- Focus loss: Improved bounding box prediction for small objects.
- Data Augmentation Techniques: Enhanced model generalization through data manipulation.
YOLOv6 (2022)
Reintroduced aspects of the original YOLO design for faster inference speed. It Incorporated innovations like:
- Equivariant Adaptive Feature Sampling (EA-SA): Enhanced feature extraction for objects at different scales.
- SiPE (Scale Prediction Error): Improved bounding box size prediction.
YOLOv7 (2022)
Focused on pushing the boundaries of real-time performance:
- Utilizes EfficientDet backbone: Achieves high accuracy with fewer parameters.
- Focuses on model optimization techniques: Reduces computational cost while maintaining good accuracy.
YOLOv8 (2023)
- Previous Versions: Leverages the strengths of previous versions, striking an exceptional balance between speed and accuracy.
- Advanced Techniques Integration: Employs advanced techniques like path aggregation networks (PAN) for better feature fusion and utilizes focus loss for refined bounding box prediction.
This evolutionary journey showcases the continuous advancements in the YOLO series. YOLOv8 is a testament to the ongoing quest for real-time object detection with ever-increasing accuracy.
Understanding the YOLOv8 Object Detection Framework
YOLOv8 is a remarkable computer vision model developed by Ultralytics, which is known for its superior performance in object detection, image classification, and segmentation tasks.
For the YOLO (You Only Look Once) series of models, this model offers significant improvements in accuracy, modeling architecture, and developer experience.
This summarises its methodology, how it compares to other approaches, and its key strengths and weaknesses.
YOLO’s Object Detection Framework
YOLO takes a single-stage approach, unlike traditional two-stage detection methods that involve separate stages for proposal generation and classification. Here’s the gist.
- Image Preprocessing: The input image is divided into a grid of cells.
- Feature Extraction: A convolutional neural network (CNN) extracts features from the image.
- Per-Cell Predictions: Each cell in the grid predicts:
- Bounding boxes: The model predicts the number of bounding boxes for each cell which are defined in different sizes.
- Confidence Score: Each bounding box is predicted to have a confidence score, indicating the likelihood of having an object and correct class in it.
- Class Probabilities: The model predicts the probability of each object class (e.g., car, person) for each bounding box.
- Non-Maximum Suppression: To eliminate duplicate predictions, non-maximum suppression is applied to the bounding boxes.
- Output: The final output includes the bounding box with the highest confidence score and its corresponding class probability.
YOLO Compared to Other Approaches
- R-CNN (Region-based Convolutional Neural Network): This two-stage approach involves proposing regions of interest (potential objects) and then classifying them. It’s more precise, but it’s not faster than YOLO.
- SSD (Single Shot MultiBox Detector): Like YOLO’s single-stage approach, SSD uses predefined anchor boxes of various sizes and aspect ratios at different feature map locations. However, the YOLO system generally achieves higher accuracy in benchmark data.
YOLO’s Advantages and Disadvantages
Advantages
- Real-time Performance: YOLO excels at speed, making it suitable for real-time applications like autonomous vehicles.
- Simplicity: The single-stage approach simplifies the training process compared to two-stage methods.
- Strong Backbone Networks: YOLO often utilizes powerful backbone networks like Darknet or EfficientDet, which contributes to its accuracy.
Disadvantages
- Accuracy Trade-off: While improving, YOLO’s accuracy can still lag behind some two-stage detectors in specific scenarios.
- Small-Object Detection: YOLO might struggle to detect very small objects compared to other models.
- Localization Issues: In some cases, bounding box localization accuracy might be slightly lower than that of two-stage detectors.
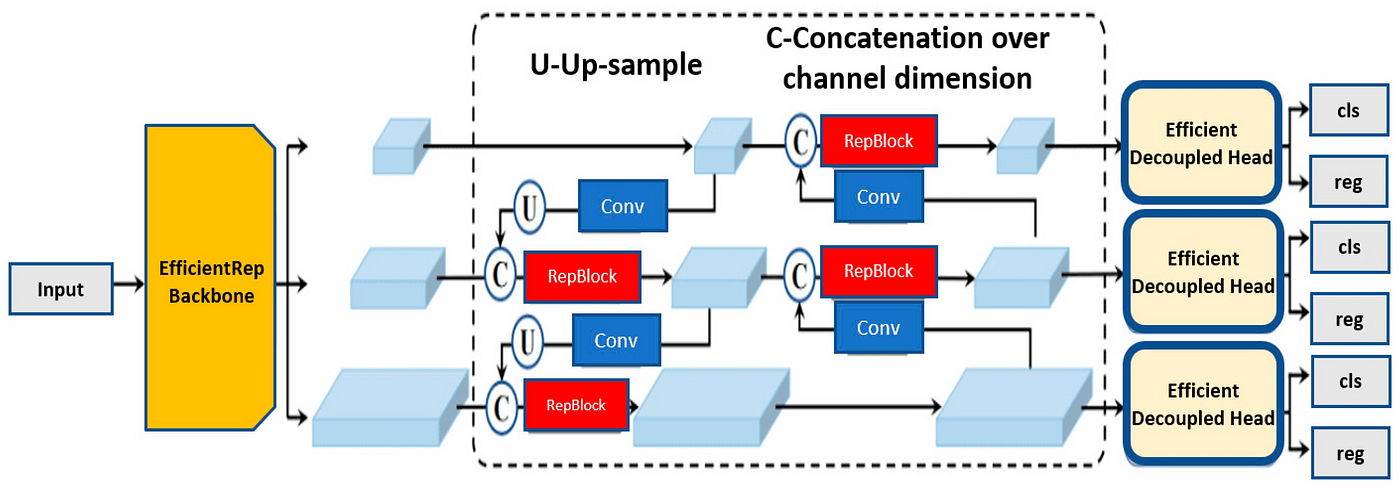
Breaking Down the YOLOv8 Architecture: Step-by-Step
yolov8 architecture is the backbone of its exceptional object detection capabilities. Let’s explore each key stage, understanding its role in transforming an image into a set of identified objects:
1. Powerful Backbone
YOLOv8 uses pre-trained convolutional neural networks, such as Darknet or Efficient-53Det, to extract valuable features from input images.
These features are designed to capture essential information about the content of the image and to lay the foundation for object detection.
2. Refinement and Enhancement
YOLOv8 may utilize techniques like.
- Spatial Attention ModuleSAM: This module is designed to focus the model’s attention on the most important areas of the extracted features, improving the detection of small or occluded objects.
- Path Aggregation Network (PAN): This network merges features from different network layers, combining low-level details with high-level semantic information to create a more comprehensive understanding of the image.
3. The Prediction Layers
- Grid Division: The image is divided into a grid of cells, like a 16×16 grid. Each cell acts as a zone for potential object detection.
- Per-Cell Predictions: Within each cell, the model predicts:
- Bounding Boxes: Predicts several bounding boxes of various sizes and aspect ratios, representing potential object locations within that cell.
- Confidence Scores: The model predicts a confidence score for each bounding box, indicating its belief that the box contains an object and the correct class.
- Class Probabilities: Predicts the probability of each object class for each bounding box, allowing for object classification.
4. Loss Functions
During training, loss functions like Intersection over Union (IoU) loss and classification loss play a crucial role.
- IoU Loss: Penalises incorrect box bounding predictions, ensuring a tight enclosure around the actual objects.
- Classification Loss: Minimizes errors in predicting class probabilities, leading to more accurate object classifications.
5. Output and Post-processing
After processing the image, YOLOv8 generates a final output containing
- Bounding boxes for detected objects
- Confidence scores for each bounding box
- Predicted class labels for each object
- Additional techniques like Non-Maxima Suppression (NMS) might be applied to refine detections by removing redundant bounding boxes.
Key Features of YOLOV8
By combining these key features, YOLOv8 achieves a remarkable balance between speed and accuracy in object detection.
This makes it a valuable tool for various computer vision tasks requiring real-time performance and high detection capabilities.
Here’s a breakdown of the key elements that contribute to its success:
1. Improved Accuracy
YOLOv8 ensures accurate object detection in images by improving object detection accuracy through novel methodologies and optimizations.
2. Enhanced Speed
YOLOv8 is appropriate for real-time applications since it maintains excellent accuracy while achieving higher inference speeds than previous models.
3. Multiple Backbones
It gives customers the freedom to select the ideal model for their particular use case by supporting a variety of backbone designs, such as CSPDarknet, ResNet, and EfficientNet.
4. Adaptive Training
It uses adaptive training to optimize the learning rate and balance the loss function during training, leading to improved model performance.
5. Advanced Data Augmentation
YOLOv8 uses sophisticated data augmentation methods like MixUp and CutMix to improve the model’s generalization and resilience.
6. Customizable Architecture
It has an extremely adaptable design that lets users change the parameters and structure of the model to fit their requirements.
7. Pre-Trained Models
It offers a selection of pre-trained models that are simple to use and transfer learning across several datasets, allowing for rapid deployment and task-specific customization.
Applications of YOLOV8
YOLOv8’s exceptional object detection capabilities translate into a wide range of applications within computer vision. Here’s a glimpse into how it is transforming various industries:
1. Autonomous Vehicles
Yolov8 architecture is essential to autonomous driving systems since it detects traffic signs, pedestrians, and cars in real-time. Its ability to recognize and respond to items on the road ensures both safety and relaxing travel.
2. Video Surveillance
Video surveillance systems can use YOLOv8 to identify suspicious activities or watch for particular objects. It can recognize individuals entering prohibited areas or unsecured items in high-security locations, for instance.
3. Traffic Monitoring
YOLOv8 can monitor traffic flow, analyze congestion patterns, and even automatically detect accidents. This information is valuable for optimizing traffic management and improving road safety.
Challenges of YOLOv8
Even though YOLOv8 excels at object identification, it has some drawbacks. A closer look at a few of the difficulties posed by YOLOv8 is provided below:
1. Data Dependence in Training
Like the majority of sophisticated machine learning models, YOLOv8 depends on the caliber and volume of training data. The performance of the model may deteriorate if the training data do not accurately represent real-world circumstances.
2. Computational Resources
Although YOLOv8 Architecture is faster than some of the two-stage detectors, it still requires significant computational resources for training and inference, in particular when using a complex backbone network such as Darknet-53.
3. Limited Context Understanding
YOLOv8 Architecture primarily focuses on individual objects within an image. It doesn’t inherently capture the relationships between objects or the overall scene context. This might be a disadvantage for tasks requiring a deeper understanding of the image content, such as activity recognition in complex scenes.
Why Should We Choose YOLOV8?
There are several compelling reasons to choose YOLOv8 Architecture for your object detection project.
YOLOv8 is remarkably balanced between real-time performance and high-accuracy detection. It has a single-stage architecture, which makes it significantly faster than two stages of detectors, and its advanced features ensure that it is capable of delivering competitive accuracy in comparison to benchmark datasets.
Compared to some previous YOLO versions, YOLOv8 incorporates advancements that specifically address the challenge of detecting small objects within an image.
Here’s a quick decision matrix to help you compare YOLOv8 with other options
| Feature | YOLOv8 | Other Options |
|---|---|---|
| Accuracy | High and improving | Can be higher for some models, but often slower |
| Speed | Fast (Real-time capable) | Slower (Two-stage detectors might be slower) |
| Small-Object Det | Improved | This can be a challenge for some detectors |
| Bounding Box Loc. | Emphasized, often tighter bounding boxes | Might be less precise |
| Ease of Use | Pre-trained models available, easy deployment | Can vary depending on the chosen model |
| Resource Usage | Moderate (depends on backbone network) | Can vary depending on the chosen model |
Conclusion
YOLOv8 Architecture stands as the culmination of the YOLO family’s relentless pursuit of faster, more accurate, and efficient object detection. As research continues, we can expect it to be further refined and for the YOLO legacy to push the boundaries of this vital computer vision technology.
![]()
Read More:
YOLOv9 vs YOLOv8? Comparing Platform Performance

Dawood is a digital marketing pro and AI/ML enthusiast. His blogs on Folio3 AI are a blend of marketing and tech brilliance. Dawood’s knack for making AI engaging for users sets his content apart, offering a unique and insightful take on the dynamic intersection of marketing and cutting-edge technology.






