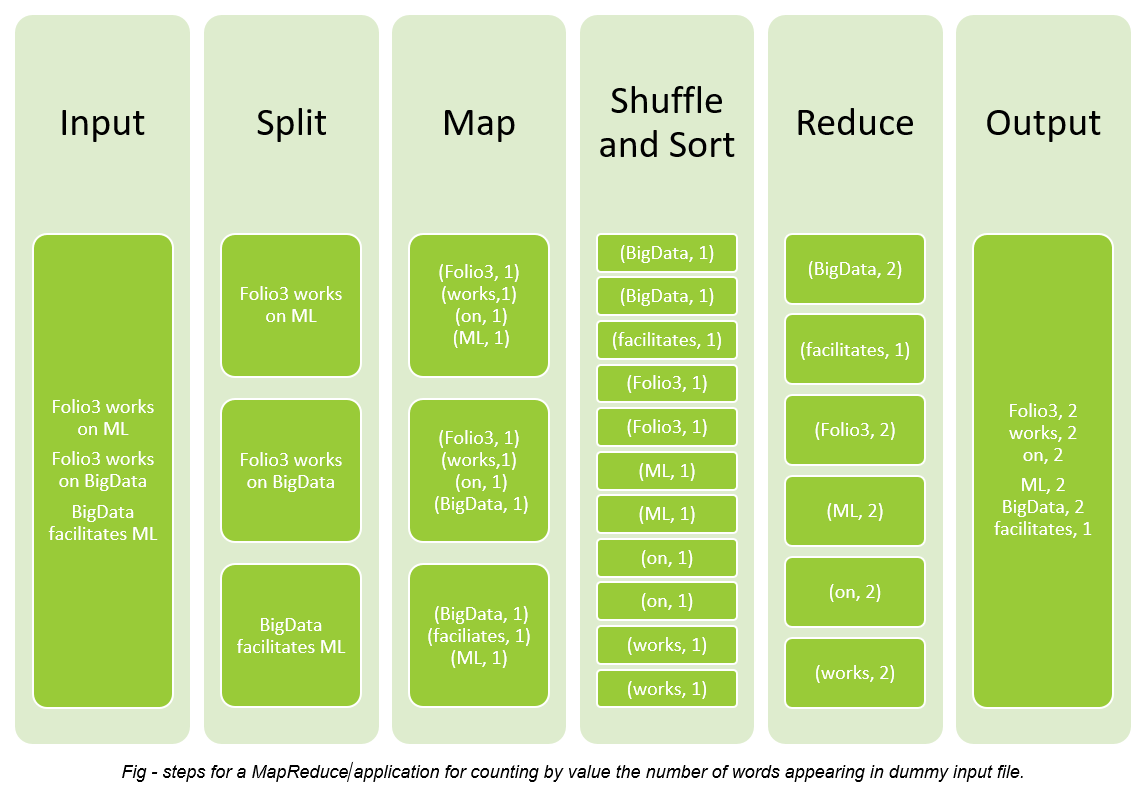
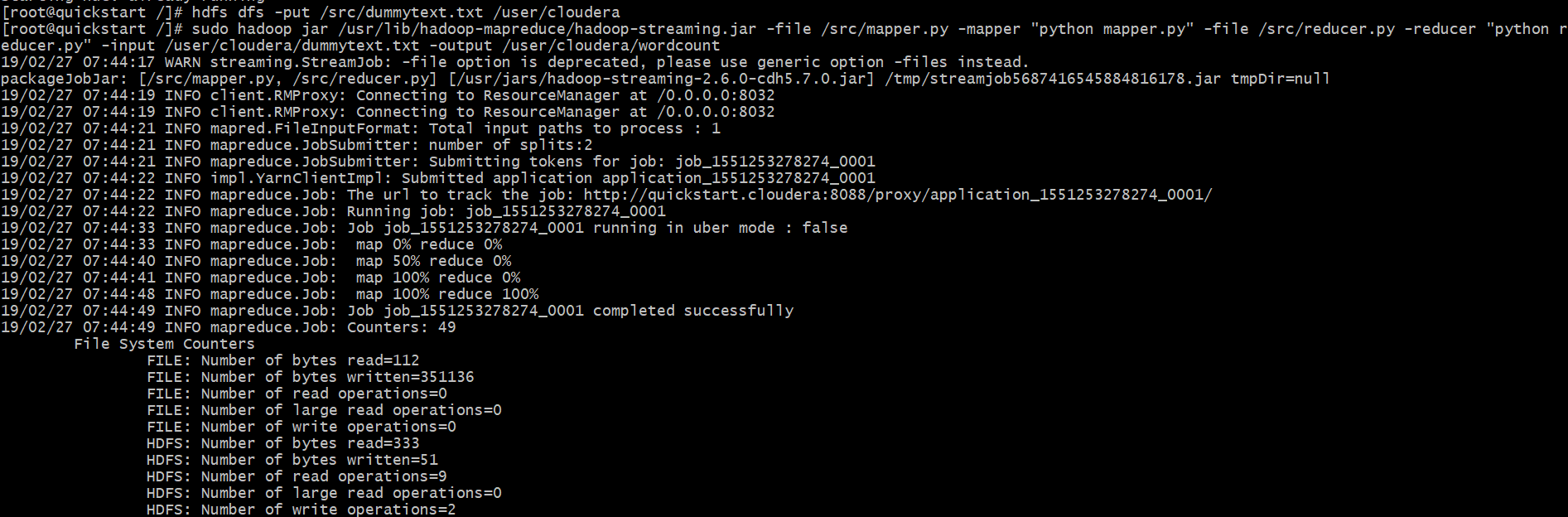
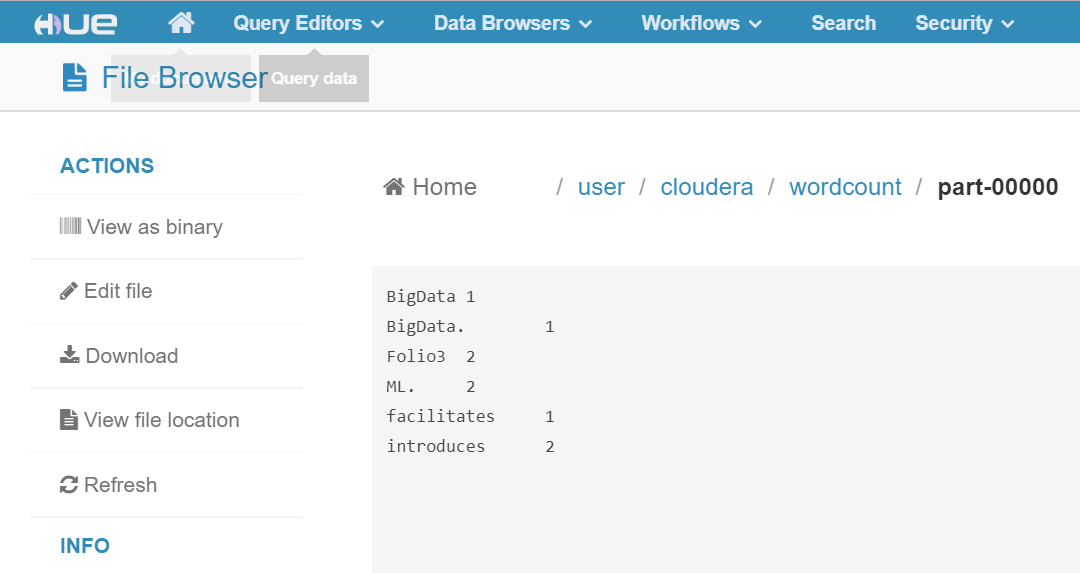
29 Best Machine Learning Software and Tools in 2020

Machine learning systems have the ability to automatically learn and improve from experience without having to explicitly modify the program. Machine learning focuses on the development of computer programs that are capable of accessing data and using it to learn for themselves. Machine learning technologies in the recent past have become quite powerful and integration of best machine learning software into our daily lives have deepened over the these years. Our dependency on this technology is likely to increase, thereby benefiting the community at large. We at Folio3 have dedicated a considerable amount of resources to this technology and have delivered numerous end-to-end projects related to machine learning solution.
15 Best Machine Learning Software in 2020
1) Amazon Machine Learning (AML) AML is a cloud-based and one of the best machine learning tools that developers with varying levels of skill levels can use. It is a managed service that is used to create machine learning models and generate predictions. Moreover, it has the capability to integrate data from multiple sources such as Redshift, Amazon S3, or RDS. Features:
- It offers wizards & visualization tools.
- Supports three types of models, i.e., multi-class classification, binary classification and regression.
- Allows users to use MySQL database and Amazon Redshift for data source object creation.
Pros:
- It can be used for ML models, Data sources, Real-time predictions, Evaluations, and Batch predictions.
Tool Cost/Plan Details: Free Download link: https://aws.amazon.com/free/machine-learning/ 2) Oryx 2 A realization of the lambda architecture and built on Apache Kafka and Apache Spark; Oryx 2 is widely used for real-time large-scale machine learning. This framework enables users to build end-to-end applications for regression, filtering, classification and clustering. Features:
- It consists of three tiers: specialization on top providing ML abstractions, generic lambda architecture tier, end-to-end implementation of the same standard ML algorithms.
- Oryx 2 is the upgraded version of Oryx 1 project.
- It has three side-by-side cooperating layers, such as: speed layer, serving layer and batch layer.
- There is also a data transport layer that shifts data between the layers and serves as a recipient of external data.
Tool Cost/Plan Details: Free Download Link: https://jar-download.com/artifacts/com.cloudera.oryx/oryx-ml/2.7.2 3) Apple`s Core ML Core ML is a data science software tool by Apple. It is a straightforward model that helps users integrate machine learning models into their mobile apps. The simple process requires users to drop the machine learning model file into their project and the Xcode automatically builds a Swift wrapper class or Objective-C. Features:
- Domain-specific frameworks and functionality can be based on it.
- Core ML easily supports Computer Vision for precise image analysis, GameplayKit for learned decision trees evaluation and Natural Language for natural language processing.
- It is optimized for on-device performance.
- It builds on top of low-level primitives.
Tool Cost/Plan Details: Free Download link: https://developer.apple.com/documentation/coreml 4) Scikit-learn Scikit-learn is for machine learning development in python; offers a library for the Python programming language. Features:
- It facilitates data mining and data analysis processes.
- It offers models and algorithms for Classification, Dimensional reduction, Regression, Clustering, Model selection and Pre-processing.
Pros:
- Provides comprehensible documentation.
- When calling objects, parameters for specific algorithms can be changed.
Tool Cost/Plan Details: Free Download link: https://scikit-learn.org/stable/install.html 5) Pytorch PyTorch is a Python machine learning library based on Torch, which is basically a Lua based scripting language, computing framework and machine learning library. Features:
- It helps build neural networks through Autograd Module.
- It offers a number of optimization algorithms for building neural networks.
- It can be used on cloud platforms.
- PyTorch has distributed training, many tools and libraries.
Pros:
- Users can easily create computational graphs.
- Hybrid front-end makes it easy to use.
Tool Cost/Plan Details: Free Download link: https://pytorch.org/ 6) TensorFlow TensorFlow offers a JavaScript library which facilitates machine learning. Available APIs help you build and train the models. Features:
- It helps in preparing and building your models.
- You can run your current models with the assistance of TensorFlow.js (a model converter).
- It helps in the neural network.
Pros:
- It can be used in two ways, i.e. by script tags or by installing through NPM.
- It can even facilitate human pose estimation.
Cons:
- It is difficult to learn.
Tool Cost/Plan Details: Free Download link: https://www.tensorflow.org/install 7) Weka Weka enables machine learning algorithms that help in data mining. Features: It assists in Data preparation, Classification, Regression, Clustering, Visualization and Association rules mining. Pros:
- Provides online courses for training.
- Easy to understand algorithms.
- It is good for students as well.
Cons:
- Not much documentation and online support are available.
Tool Cost/Plan Details: Free Download link: https://sourceforge.net/projects/weka/ 8) KNIME KNIME is a tool for big data solution, reporting and integration platform. Based on the data pipelining concept, it combines different elements for machine learning and data mining. Features:
- It can integrate the code of programming languages such as JavaScriptC, Java, C++, R, Python, etc.
- It can be utilized for business intelligence, CRM and financial data analysis.
Pros:
- It serves as a good SAS alternative.
- It is easy to deploy, install and learn.
Cons:
- It is not easy to build complicated models.
- Offers limited exporting and visualization capabilities.
Tool Cost/Plan Details: Annual Subscription (based on 5 users and 8 cores) KNIME Server for Azure 25.000 EUR 29,000 USD KNIME Server for AWS 45.500 EUR 52,000 USD Download link: https://www.knime.com/downloads 9) COLAB Google Colab is a cloud service that supports Python. It utilizes PyTorch, Keras, TensorFlow, and OpenCV libraries in order to help you build machine learning applications. Features: It assists in machine learning education and research. Pros: You can access it via your google drive. Tool Cost/Plan Details: Free 10) APACHE Mahout Apache Mahout assists mathematicians, statisticians and data scientists in building and implementing their own algorithms. Features:
- It offers algorithms for Pre-processors, Regression, Clustering, Recommenders and Distributed Linear Algebra.
- Java libraries are incorporated for regular math operations.
- It follows Distributed linear algebra framework.
Pros: It works for large data sets. Is simple and extensible. Cons:
- Limited documentation and algorithms.
Tool Cost/Plan Details: Free Download link: https://mahout.apache.org/general/downloads 11) Accord.Net Accord.Net offers Machine Learning libraries for ai image and audio processing. Features:
- It provides algorithms for Numerical Linear Algebra, Numerical optimization, Statistics and Artificial Neural networks.
- Plus, for image, audio & signal processing.
- It also provides support for graph plotting and visualization libraries.
Pros: Libraries are made available from the source code and as well as executable installer & NuGet package manager. Cons:
- It supports only Net supported languages.
Tool Cost/Plan Details: Free Download link: http://accord-framework.net/ 12) Shogun Shogun provides numerous algorithms and data frameworks for machine learning. These machine learning libraries can be used for research and education. Features:
- It has support vector machines that can be used for regression and classification.
- It assists in implementing Hidden Markov models.
- It offers support for various languages including – Python, Scala, Ruby, Java, Octave, R and Lua.
Pros:
- It is easy to use and can process large data-sets which have been used for edge analytics services.
- It offers good customer support, features and functionalities.
Tool Cost/Plan Details: Free Download link: https://www.shogun-toolbox.org/install 13) Keras.io Keras, written in Python is an API for neural networks that assists in carrying out quick research. Features:
- It can be utilized for easy and fast prototyping.
- It supports convolution networks and a combination of two networks.
- It assists recurrent networks.
- It can be run on the CPU and GPU.
Pros:
- It is extremely user-friendly
- It is both modular and extensible
Cons:
- In order to use Keras, you must need TensorFlow, Theano, or CNTK.
Tool Cost/Plan Details: Free Download link: https://keras.io/ 14) Rapid Miner Rapid Miner is a platform for machine learning, deep learning, text mining, data preparation and predictive analytics. It is mostly used for research, education and application development. Features:
- Through GUI, it helps in structuring and implementing systematic analytical workflows.
- It assists with data preparation.
- Result visualization.
- Model approval and optimization.
Pros:
- Extensible through plugins.
- Simple to use.
- Limited programming skills required.
Cons: Rapid Miner is costly. Tool Cost/Plan Details:
- Free plan
- Small: $2500 per year.
- Medium: $5000 per year.
- Large: $10000 per year.
Download link: https://rapidminer.com/get-started/
Best Machine Learning Framework/Technology in 2020
15) Tensorflow Framework TensorFlow is an open-source software library for data-based programming across tasks. This data science software tool is based on computational graphs which is basically a system of codes. Every nod represents a numerical activity that runs some basic or complex function. This framework is one of the best Machine Learning software, as it supports regressions, classifications and neural networks such as complicated tasks and algorithms. 16) FireBase ML Kit Firebase is another prominent machine learning framework that enables highly accurate and pre-trained deep models with minimal code. The framework offers models both on the Google cloud and locally. 17) CAFFE (Convolutional Architecture for Fast Feature Embedding) CAFFE framework provides the quickest solution to applying deep neural networks. It is the best Machine Learning framework known for its pre-trained model-Zoo, which is capable of performing a plethora of tasks including image classification, recommender system and machine vision. 18) Apache Spark Framework A cluster-computing framework, the Apache Spark machine learning is written in different languages like Java, Scala, Python and R. Spark’s Machine Learning library, MLlib has aided Spark’s success. Building MLlib on top of Spark enables it to tackle distinct needs of a single tool, as opposed to many disjointed ones. 19) Scikit-Learn Framework One of the best tools of Python community, Scikit-learn framework can efficiently handle data mining and support numerous practical tasks. It is built on foundations like SciPy, Numpy, and matplotlib. This framework offers supervised, unsupervised learning algorithms and cross-validation. The Scikit is mostly written in Python with some core algorithms in Cython for enhanced performance.
Best Open Source Machine Learning Tools in 2020
20) Uber Ludwig - Open Source Machine Learning Tool for Non-Programmers It is a toolbox built on top of TensorFlow that allows users to train and test deep learning models without having to write any code. It enables users to build complex models that they can tweak before implementing it into code, with minimal input. 21) MLFlow - Open Source Machine Learning Tool for Model Deployment It can seamlessly work with any machine learning library or algorithm, enabling it to manage the entire lifecycle, including experimentation, reproducibility and deployment of machine learning models. One of the best machine learning tools, MLFlow is currently in alpha and its three components are: projects, tracking and models. 22) Hadoop - Open Source Machine Learning Tool for Big Data Hadoop project is a prominent and relevant tool for working with Big Data. It is a framework that enables distributed processing of large datasets across clusters of computers using simple programming models. It has the capability to scale up from a single server to thousands of machines, each offering local computation and storage. 23) SimpleCV - Open Source Machine Learning Tool for Computer Vision SimpleCV enables access to several high-powered computer vision libraries like OpenCV - making computer vision relatively easy. This can be done without having to learn about bit depths, file formats, color spaces, buffer management, eigenvalues, or matrix versus bitmap storage. 24) Reinforcement Learning - Open Source Tool for Reinforcement Learning RL is a popular phenomenon in Machine Learning and its goal is to train smart agents that can automatically interact with their environment and solve complex tasks. Real-world applications of this technology include robotics and self-driving cars, amongst others.
Best Machine Learning Software Alternatives
25) ServiceNow Platform Its intelligent engine is combined with Machine Learning to create contextual workflows and automate business processes. This helps reduce costs and speed time-to-resolution. 26) Qubole It delivers optimized responses of Big Data Analytics built on Amazon, Microsoft and Google Clouds. 27) Weka Weka contains tools for data pre-processing, classification, regression, clustering, association rules and visualization. It is also be utilized for developing new Machine Learning schemes. 28) IBM Watson Machine Learning It allows you to create, train and deploy machine learning models using your own data; enabling you to grow intelligent business applications. 29) BigML It is easier to set-up and enables users to enjoy the benefits of Programmatic Machine Learning.
Best Machine Learning Software FAQs:
Is Tensorflow framework used for Machine Learning only?
A creation of Google Brain team, TensorFlow is an open source library for numerical computation and large-scale machine learning. It can be used for a wide range of Machine Learning and deep learning applications. It combines machine learning and deep learning (aka neural networking) models/algorithms, making them useful by way of a common metaphor.
How to build a simple stock prediction software using Machine Learning?
Basic machine learning models on stock market data to predict future trends can be built using a single attribute i.e stock price to analyze the trend of stock. Or it can be achieved by simply opting for ARIMA, which is one such statistical model for time-series and atm cash forecasting that stands for Autoregressive Integrated Moving Average. And assumes that time-series information is data points measured at constant time intervals, such as hourly, weekly so and so forth.
Best way to incorporate Machine Learning to your App software?
Data forms the basis and the more data is provided to the algorithm and simpler the model, the better the accuracy of predictions. Hence, it is best to avoid subsampling. The success of the project depends on choosing the most appropriate Machine Learning method and right parameters. Proper data collection and understanding data features also impact learning processes and predictability. Additionally, you need to consider your business model and product capacities. Also keep in mind that algorithms need to be tested, which could increase the time and cost.
How much does a Machine Learning software engineer make?
Machine learning software engineers are in high demand, which reflects in their salary and benefits packages. It is without a doubt one of the best jobs out there, outpacing many other technology jobs. Average machine learning salary, according to Indeed’s research, is approximately $146,085 (which has increased by 344% since 2015). An entry-level machine learning engineer with 0-4 years of experience would on an average make approximately $97,090. This can go up to $130,000 if there is profit-sharing or bonuses involved. Mid-level machine learning engineers with 5-9 years of experience command an average salary of $112,095. The number can rise to $160,000 or more, depending on bonuses and profit-sharing. Senior machine learning engineers with over a decade of experience are the industry’s unicorns and command the best remuneration packages in the field. The are likely to make an average salary of $132,500, surpassing $181,000 annually with bonuses and profit-sharing.
Why You Need Machine Learning Software For Every Industry
Machine learning software is used to automate various company processes, across industries to boost productivity, such as enabling customer interactions to be carried out without human input. These machines are algorithms designed to process large amounts of information and make logical decisions. The machines are therefore programmed to learn and complete tasks without requiring any further programming. 1) Transportation Industry We are all aware of how unsmart traffic lights are, but with Machine Learning as a service and Artificial intelligence algorithms they can efficiently predict, monitor and manage the traffic. Best machine learning tools are also being utilized by car manufacturers like Tesla to introduce self-driving cars that can regulate speed, change lanes and park - without human assistance. 2) Healthcare Industry From radiology to diagnostics purposes, intelligent softwares are being employed to not only predict the likelihood of a disease occurring but also to suggest the best possible way to prevent/cure the disease. These are faster in detecting and scanning information, enabling them to produce results much more quickly than humans. 3) Finance Industry Machine Learning applications such as Robo-Advisors are already being used in the finance industry to simplify the investment process and as a cheaper alternative to hiring a human financial advisor. They employ Machine Learning algorithms to automate financial guidance to manage portfolios. Moreover, trading platforms such as High-Frequency Trading (HFT) is being employed by investment banks, pension funds and mutual funds, whereby allowing them to benefit from minute price differences that surface for a fraction of a second. 4) Agriculture Industry We are all aware of approaches that predict crop yields based on historical data and multi-parametric approaches that help optimize productivity; but now algorithms are being utilized to understand the crop quality, identify diseases and detect weeds. Machine Learning is also being utilized to study soil moisture and temperature of fields to understand the dynamics of ecosystems and obstacles. Machine Learning based apps are successfully enabling farmers make better use of irrigation by providing accurate estimates of evapotranspiration. 5) Education Industry Machine Learning is being used by learning platforms like Udemy, Teachable and WizIQ to provide personalized academic lesson recommendations; similar to how YouTube does it. It is also helping educators become more efficient by automating tasks such as classroom management and scheduling.
Start Gowing with Folio3 AI Today.
We are the Pioneers in the Cognitive Arena - Do you want to become a pioneer yourself ?Get In Touch
Please feel free to reach out to us, if you have any questions. In case you need any help with development, installation, integration, up-gradation and customization of your Business Solutions. We have expertise in Machine learning solutions, Cognitive Services, Predictive learning, CNN, HOG and NLP.
Connect with us for more information at Contact@184.169.241.188


 The installation syntax for this package is:
The installation syntax for this package is: