


Artificial intelligence is an emerging technology. It is impacting the interactive activities of users through the internet.
It can change how humans interact, not only with the digital and electronic world but also with each other.
It is a form of technology with human-like intelligence that can learn, perceive, plan, and process languages. There are two categories of AI, which include “narrow AI” or “general AI.”
Narrow AI is domain-specific that we interact with today. By domain-specific, we mean, for instance, language translation.
General AI is theoretical and not domain-specific. Just to remain in the context, we would focus only on narrow AI.
It is a machine language – a field of computer science for the development of new algorithms and models. Conversely, we can say machine language is an application of Artificial Intelligence.
The list of machine languages is vast, with several different categories.
Here we are going to discuss R – a programming language in detail. The language falls in the category of Array languages. So, what is R? R comprises many properties.
It is a machine language that provides an open-source environment for statistical programming and visualization. There are many R machine learning packages, which we will be discussing in detail.
You can find seamlessly designed AI solutions such as R learning packages in the market by machine learning solution companies such as Folio3.

21 Best R Machine Learning Packages
The most commonly asked question by potential data scientists is, “What is the best programming language for Machine Learning as a service?”
The answer to this question always ends up in a debate about whether to choose R, Python, or MATLAB for Machine Learning.
Choosing the programming language for machine learning depends on the requirements of a data problem, and the preferences of the data scientist.
According to the Kaggle survey, open-source R is the preeminent choice among data specialists who want to understand and explore data by using statistical methods and graphs.
There are many R machine learning packages and their advanced implementations for the top machine learning algorithms.
Every data specialist must be familiar with them to explore, model, and create a prototype of the given data. Since R is an open-source language, people can approach it from anywhere in the world.
From data collection to reproducible research, you can find a Black Box written by someone else that you can use in your program directly.
The Black Box is nothing but a Package in R, which is a collection of pre-written reusable codes. Here are a few basic R-learning machine packages:
1) CARAT
The CARAT package denotes Classification and Regression Training. The purpose of this package is to integrate training and model prediction.
It allows data specialists to run several different algorithms for a given problem. It also facilitates investigating the ideal parameters for an algorithm with measured experiments.
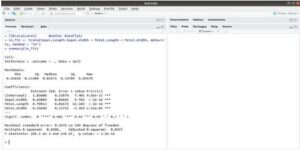
CARAT Features And USP: The grid search method of this package explores parameters with the help of a combination of various methods to evaluate the performance of a given model.
After having a look at all the trial combinations, the grid search method discovers the combination that gives the best results.
CARAT package is among the best machine learning packages in R. After installing the CART package; a developer can run names (getModelInfo()) to see that 217 possible methods require a single package to operate or run.
To build any predictive model, CARAT uses the train() function; The syntax of the train function is trained (formula, data, method).
CARAT Documentation Download: The CARET package is not only for building models, but it also takes care of splitting your data into test and train, alteration, etc.
2) Random Forest
The concept behind its name is to “combine multiple trees to build your forest.” A Random Forest algorithm is the most widely used algorithm in Machine Learning.
Its application includes the creation of a large number of decision trees, and then each observation is entered into the decision tree.
The common output attained for a maximum of the observations is measured as the final output.
In other words, it takes random samples. Observations are arranged into the decision tree.
While using the randomForest algorithm, data specialists have to confirm that the variables must be numeric or factors.
Factors cannot have more than 32 levels when applying randomForest. This package allows for solving regression and classification tasks.
Training missing values and outliers is one of its many applications. The syntax of this function is randomForest(formula=, data=)
3) E1071
The name of this package seems a junk value, but this is not the case. It is a very significant package in the R machine learning package.
It has very specified functions for implementing Naïve Bayes (conditional probability), SVM, Fourier Transforms, Bagged Clustering, Fuzzy Clustering, etc.
E1071 R package implemented the first R interface for SVM.
E1071 Documentation Download: The easy way to understand its concept is, let’s suppose if a data specialist is trying to find out what is the probability that a person who buys an iPhone 8 also buys an iPhone 8 Case.
It is a type of investigation that depends on conditional probability, so data scientists use an e1071 R package that has specialized functions for implementing the Naive Bayes Classifier.
Data scientists use Support Vector Machines (SVM) when they have a dataset that is impossible to separate in the given dimensions, and there is a need to promote that data to higher dimensions to classify or regress it.
The syntax for SVM is: SVM(Species ~Sepal.Length + Sepal.Width, data=iris)
4) RPart
Rpart stands for recursive partitioning and regression training. Classification and regression are the two primary purposes of this package.
It involves a two-stage procedure. The output model is then represented in the form of binary trees. The general way to plot any function using the Rpart package is to call plot() function.
The results might not be appealing by just applying the basic plot() function, so there is a substitute that is the PRP() function. It is an influential and flexible function in part.plot package.
It is frequently denoted as the authentic Swiss army knife for plotting regression trees.
rpart() function helps to create a relationship between dependent and independent variables so that a business can understand the difference in the dependent variables based on the independent variables.
The syntax is: rpart(formula, data=, method=,control=) This formula implies as follows: Data implies the name of the dataset. The method implies the objective. Control implies the system requirement.
5) KernLab
KernLab is a package for SVM, kernel feature analysis, ranking algorithm, dot product primitives, Gaussian process, and a spectral clustering algorithm.
KernLab’s most common use is for SVM implementations. It comes in use when it is difficult to solve clustering, classification, and regression problems.
It has several kernel functions that include tanhdot (hyperbolic tangent kernel Function), polydot (polynomial kernel function), laplacedot (laplacian kernel function) and many more to perform pattern recognition problems.
KernLab has its predefined kernels, but the user has the flexibility to create and use their kernel functions.
6) Nnet
Data scientists use this package when there is a need to use an artificial neural network (ANN) as it is based on an understanding of how a human brain functions.
It is one of the widely used and easy to implement a package of neural networks, but it is restricted to a single layer of nodes.
According to several studies, more nodes are not required because they do not contribute to improving the performance of the model but rather increase the calculation time and complexity of the model.
This package does not offer any particular set of methods for finding the number of nodes in the hidden layer.
Thus, when data specialists apply nnet, it is most likely recommended that they arrange it in such a way that a value falls between the number of input and output nodes.
The syntax for this package is: nnet(formula, data, size) To view the documentation of its function, go to this link: https://www.rdocumentation.org/packages/nnet/versions/7.3-12/topics/nnet
7) DPLYR
Dpylr is one of the most popular packages in the field of data science. It provides feasible, fast, and stable functions for data handling.
This package contains some set of verbs as functions like mutate(), select(), filter(), and arrange().
The following code is used to install this package: install.packages(“dplyr”) To load this package the following syntax is used: library(dplyr)
8) GGPlot2
Ggplot2 is another package for data science. It is the most sophisticated and artistic graphic framework among R packages.
The syntax for the installation of this data science package is install.packages(“ggplot2”)
9) Word Cloud
Word cloud, as the name indicates, consists of thousands of words in a single image.
Conversely, we can say that it is a visualization of text data. One great example is speech-to-text software. It is one of the best machine learning packages in R that creates a representation of words.
Data specialists can customize the Worldcloud according to his choice. He can place the words randomly in his desired
In the R machine learning package, two types of libraries are there to make Worldcloud that are Worldcloud and Worldcloud2.
Here we will present the syntax of Worldcloud2. The installation syntax for Worldcloud2 is:
- require(devtools)
- install_github(“chiffon/wordcloud2”)
Or you can write it directly as a library(wordcloud2).
10) Tidyr
It is another popular R package for data science. The function of the tidyr package for data is science is to tidy up the data.
It is done by placing variables in the column, observation in the row, and the value in the cell. This package is used to define the standard way of organizing data.
For installation syntax, use this code: install.packages(“tidyr”) For loading the package, use this code: library(tidyr)
11) Shiny
Shiny is an R package, the use of which stretches to web application frameworks for data science.
It provides an effortless solution for building up web applications. There are two options, the developer can install the software on every client system, or he can host a webpage.
In addition, the developer can create dashboards or can implant them in R Markdown documents.
Furthermore, Shiny apps can be used with various scripting languages like HTML widgets, CSS themes, and JavaScript actions.
Conversely, this package is considered as a combination of the computational power of R with the interactivity of the modern web.
12) Tm
Tm is a machine learning package of R that gives a framework for solving text mining tasks. Text mining is an evolving application of natural language processing these days.
Text mining application involves sentiment analysis or news classification. There are several jobs for a developer that he has to perform in this package, such as eliminating unwanted and unrelated words, eliminating punctuation signs and ending words, etc.
This package has many adaptable functions to provide ease. Some of them are as follows:
- removeNumbers(): to remove Numbers from the given text document.
- weightTfIdf(): for term Frequency and reverse document frequency.
- tm_reduce(): to combine transformations.
- removePunctuation() to remove punctuation signs from the given text document.
13) MICE Package
MICE package refers to Multivariate Imputation via Chained Sequences. One of the many uses of this package includes imputing the missing values.
It is a common problem that developers usually face. Generally, when a developer faces a problem of missing values, he applies basic imputations like replacing with 0, mean or mode, etc.
These solutions are not flexible and may result in possible data inconsistency.
Therefore MICE package facilitates developers to impute missing values with the help of multiple techniques according to the type of given data.
This package consists of various functions like inspecting missing data patterns, diagnosis of the quality of the imputed value, analyzing completed datasets, storing and exporting imputed data in different structures, etc.
For the package documentation, click on this link https://www.rdocumentation.org/packages/mice/versions/3.6.0/topics/mice
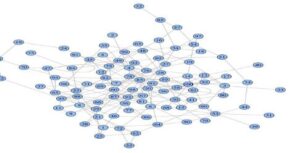
14) iGraph
igraph is one of the top machine learning R packages for data science used for network analysis. It is a combination of powerful, professional, accessible, and portable network analysis tools.
Moreover, it is an open-source and free package and can be programmed on Python, C/C++, and Mathematica.
This package consists of numerous functions that help to produce random and regular graphs, visualization of a graph, etc in computer vision.
By using this R package, developers can work on their huge graphs. There are some specific requirements to use this package for Linux. It needs a C and a C++
The installation syntax for this package is: install.packages(“igraph”) The loading syntax for this package is: library(igraph)
15) ROCR
This data science R package helps in visualizing the performance of scoring classifiers. This package is flexible and feasible.
It requires only three commands and default values for optional parameters. This package facilitates in development of cutoff-parameterized 2D performance curves.
This package comprises of various functions such as prediction() – used to create prediction objects performance() – used to create performance objects, etc.
For package documentation, view this link https://www.rdocumentation.org/packages/ROCR/versions/1.0-7
16) Data Explorer
The DataExplorer package is among the widely used and top machine learning R package for data science.
This package serves in the field of exploratory data analysis (EDA), which is one of the predictive analytics tasks.
As the name implies, in this package, the data analyst has to be more attentive in data analysis. It is not easy to handle data manually.
For this purpose, the DataExplorer package provides automation for data exploration. This package helps in scanning and analyzing every variable to visualize them.
It is beneficial for a huge dataset. The data analysis can easily obtain the hidden knowledge of data.
You can use this mentioned code to install the package from CPAN: install.packages(“DataExplorer”) To load this package, the following code is needed: library(DataExplorer)
17) MLR
The mlr package of machine learning is one of the most amazing packages. It provides encryption to various machine learning tasks.
It can perform several tasks with the help of only a single package rather than to use three packages for three different tasks.
mlr package provides coherence for various classification and regression techniques. The tehttps://web.archive.org/web/20210227030942/https://www.rdocumentation.org/packages/mlr/versions/2.15.0chniques involve machine-readable parameter descriptions, clustering, generic re-sampling, filtering, and feature extraction, etc.
It can also perform parallel operations. For installation, this code is used: to install.packages(“mlr”) The code for loading this package is; library(mlr)
18) Arules
The arules package rules refer to Mining association rules and Frequent Itemsets. It is also a widely used R machine learning package.
This package helps in performing several operations that include representation and transaction analysis of data and patterns and data manipulation.
It also provides the C implementations of Apriori and Eclat association mining algorithms.
19) Mboost
mboost is another R machine learning package for data science. It is a package that depends majorly on model boosting.
It has an operative gradient descent algorithm for enhancing general risk functions. It uses regression trees or component-wise least squares estimates.
Also, it provides an interaction model to potentially high-dimensional data
20) Party
The applications of the Party package in R machine learning extend to recursive partitioning. This package imitates the continuous development of collective methods.
Party is another package like a randomForest package to make a decision tree, which is based on the Conditional Inference algorithm.
The main function of this package is ctree() which reduces the training time and bias. The syntax code for ctree() is: ctree(formula,data)
Folio3 AI Is Your Best Custom Machine Learning As a Service Partner
Folio3 AI is a leading software company, providing customized solutions in machine learning. With the prolonged experience of decades, Folio3 has helped many partner companies from various industries.
It has the expertise of AI and machine learning in the following processes.
- Product Conceptualization
- Predictive Engineering and maintenance analysis
- Design and Automation
- Data Acquisition and Analytics
- Product planning and commissioning
- Utilizing operational data to improve processes
Folio3 can also alter and customize the development process according to your requirements. Their professional and talented team follows the predefined and standard process based on best practices :
- Submission of hypothesis
- Scope and feasibility of the project defined Delivery of a Proof of Concept
- Algorithm development with regular touchpoints Final delivery and live deployment
Folio3 is capable of understanding customer needs and hence able to create machine learning solutions accordingly.
Artificial Intelligence and machine learning help to develop great projects, but it is also important to provide the best user experience.
, Folio3 supports regular interaction with customers and related stakeholders. Folio3 has delivered its efficient services in many industries. Here we are mentioning nine among them and their related use cases:
1) Banking Sector – ATM Cash Forecasting
Folio3 has provided its assistance to the multinational and large commercial banks of Pakistan. It served them with the service of deep learning for ATM cash Forecasting.
It helps banks avoid both out-of-cash and overstock situations at their ATMs across the world.
It also provides automated analysis of previous transactions for predicting the required amount of money for individual ATMs.
2) Health Sector – Breast Cancer HER2 Subtype Identification
Folio3 provided the solution of computer vision for Breast Cancer HER2 subtype identification to one of the most popular universities of Pakistan, Dow University of Health Sciences.
The solution provides an automated pipeline for cell segmentation and spot counting from a Computer Vision-based diagnostic aid for the Fluorescent In-Situ Hybridization test.
For this reason, Folio3 developed a computer-supported assistance system that allowed specialists to perform the test efficiently and accurately and also allowed them to digitize and store the images for future practice.
3) Transportation Sector – Road Traffic Analysis
It was a propriety service of deep learning by Folio3 for the transportation sector.
They built an AI-powered Road & Safety solution, which allowed the analysis of road and traffic situations by making use of advanced deep learning.
It can precisely distinguish between various types of vehicles and perform a total count.
4) Trading Sector – Completion Time Estimation
Folio3 has provided its services to the largest bookseller company in the United States in the area of machine learning.
The solution has enabled the customer’s Digital Marketing Team to considerably improve the effective delivery through accurate schedules and outcomes of marketing campaigns while meeting the weekly related deadlines.
5) Medical Diagnosis – Thalassemia Identification
Folio3 again served the Dow University of Health Sciences for Thalassemia Identification, a project of image analysis and AI image processing.
The solution provides automated analysis of gel electrophoresis images to predict thalassemia and test for mutant gene expression with fine-granularity medical image analysis.
6) Food Sector – Automated Authentication for Drive-Thrus
Folio3 served the product development company in California named “Dashcode.” They created the automated authentication for a drive-thru, which is a project of deep learning.
The solution offers multi-modal automated authentication for drive-thrus through fine-grained car make/model classification and person identification using deep learning.
7) Speech-to-Text App – Converse Smartly
It was a proprietary application by Folio3. It allows you to make your conversations smart, intelligent, and productive with the use of machine learning, artificial intelligence, and Natural Language Processing (NLP).
8) Technology Sector – Facial Recognition system
It was also a propriety product built by Folio3. This solution offers a highly accurate facial recognition system that provides real-time results based on Histogram of Oriented Gradients (HOG) and Convolutional Neural Network (CNN).
9) IT sector – Customer Churn Prediction
Folio 3 has served as the leading tech company in Pakistan with the facility of customer churn prediction, a predictive modeling solution.
The Customer Churn Prediction offers a data-driven insight for businesses, helping them to recognize potentially unsatisfied and inactive customers in real time with business process validation.
For detailed solutions and services, Check these URLs: Terrain Mapping Livestock Management Amazon Transcribe Service Google Speech to Text Service IBM Watson Consulting Service Azure Machine Learning Service Big Data Solution Robotic Process Automation Solution Edge Analytics Services Fraud Detection Solution
Top R Machine Learning Packages Conclusion:
All R machine learning packages are the eminent choice based on their features and functions, and every package best fits according to the given data requirements.
There are some default values related to every package in R. Before the implementation of an algorithm, a data specialist or a developer must know about the numerous options available.
Entering default values will give some outcomes, but those outcomes are not likely to be accurate or optimized.
In other words, by using the definite functions of R, one can develop an efficient machine learning or data science model.
Hence, the R machine learning package is an amazing open-source RStudio tool, providing everyone to avail of the opportunity to use it.
If you find our blog useful and informative, please share it with your friends and family. If you have any further suggestions or queries, please leave a comment in our comment section.
FAQs:
Q1. Is r used for machine learning and IoT as well?
Yes, R can be used for both because R itself is a machine language applicable in machine learning for data science tasks. As we know Artificial Intelligence is associated with IoT, and we refer narrow AI to machine learning that includes R. Hence there is a strong relation between R and machine learning in IoT applications.
Q2. Advantages of r packages in machine learning?
There are several advantages of R packages in machine learning. Some of them include
- Open Source – This means everyone has the chance to avail of these packages without the need for a license and registration process.
- Ideal support for data scattering – It allows scattered data to transform into a structured and organized form.
- Variety of packages – there is a variety of packages for different data issues.
- Provides quality plotting and graphing – Packages like ggplot2 provide visual tools for plotting and graphing the data.
- Highly compatible – It is highly compatible and can be combined with many programming languages like C, C++, Python, and Java.
- platform-independent – It is independent of any platform which means it is a cross-platform machine language that can be compatible with Windows, Linux, and Mac.
- Machine learning operations – It supports many machine learning operations like classification, regression, and development of artificial neural networks.
- Constantly growing – It is progressing continuously with the addition of new features that allow developers to work efficiently without any delay.
Q3. Which packages in r provide machine learning functionality for beginners?
Here is the categorized list of R packages that are useful for beginners:
To manipulate data:
- dplyr
- tidyr
To visualize data:
- ggplot2
To model data:
- CARAT
To report results:
- Shiny
Many other R machine learning packages fall into these categories; here, we mentioned the most feasible and popular packages useful for beginners.

Dawood is a digital marketing pro and AI/ML enthusiast. His blogs on Folio3 AI are a blend of marketing and tech brilliance. Dawood’s knack for making AI engaging for users sets his content apart, offering a unique and insightful take on the dynamic intersection of marketing and cutting-edge technology.






