




A recommender system or a recommendation system (sometimes replacing “system” with a synonym such as platform or engine) is a subclass of information filtering system that seeks to predict the “rating” or “preference” a user would give to an item.
Product Association recommender comes under the category of ‘Non-personalized recommender systems’. Non-personalized for the fact that it neither relies on user’s preferences or their historical behavioral patterns, nor upon item’s own characteristics or attribute information to make recommendations; rather, recommendations are based upon overlapping customer groups and product categories.
Product Association is often confused with Collaborative Filtering. However, both of the techniques address the problem using different approaches. The main difference lies in the ‘session’ based on which any item is being recommended. In that sense, Product Association is ephemeral in nature as it is based only on the current moment setting, e.g. what a customer just added into the cart? The recommendation for next item/product will completely rely on the item just added.
On the other hand, Collaborative Filtering often comes under the category of ‘persistent’ recommenders. Based on user’s inclination for a particular genre, items that belongs to that genre and other people who have showed interest for that particular genre as well, recommendations are made. Even if a user logs out of his account on, say, Goodreads, the next time they log in, they will be seeing more or less the same recommendations as in the last session given that goodreads follow Collaborative Filtering (or any other persistent recommendation) approach. Where Product Association focuses on ‘What products frequently found together in a cart?’, Collaborative Filtering addresses ‘What products do users with interests similar to yours like?’.
Product Association is based on two entities: item-item afiniti score and the factor that binds these items together. In a typical case of an e-store, the binding factor will be common customer base for that particular item.
Product Association Recommender based on Bayesian Theorem
First idea that comes to mind to find how frequently two items are bought together (or how closely they can be associated) is to find the percentage of customers buying both the items. For example, if we say 75% of the buyers buy ‘tissue rolls’ whenever they buy ‘eggs’, it shows a high association between the two products. However, this is not a true association since ‘eggs’ are itself are a very common product and people will buy eggs whether they buy tissues or not.
To avoid such unreal associations, a modification of Bayes’ statistical theorem is used which says that the association between two products must be found relatively i.e. the probability of buying ‘Y’ and ‘X’ together should keep in consideration the probability of buying product ‘Y’ alone.
I.e.

With the intuition understood, let’s move forward to create a basic recommender system in Python based on Bayesian Theorem. Our recommender system will generate movie recommendations to the viewers based on which movie the user just watched using MovieLens dataset. Download the dataset and let’s get started!
The dataset downloaded has four different csv files. We will use ‘ratings.csv’ to track which viewers watch which subset of movies by tracking the movies they have rated and ‘movies.csv’ to map titles of movies with movieIds. First, load the files using pandas library and map movieTitles to movieIds.
import pandas as pd
import numpy as np
ratings_fields = ['userId', 'movieId', 'rating']
movies_fields = ['movieId', 'title']
ratings = pd.read_csv("ratings.csv", encoding="ISO-8859-1", usecols=ratings_fields)
movies = pd.read_csv("movies.csv", encoding="ISO-8859-1", usecols=movies_fields)
ratings = pd.merge(ratings, movies, on='movieId')
Next we will create an empty DataFrame to store movie-movie afiniti score and find afiniti score for a referenced movie against other movies based on common viewers.
Following Bayesian Theorem modification, afiniti score can be found by finding the Probability of an item Y given item X, divided by total probability of item Y.
By translating the equation to our scenario, we will calculate afiniti score for a movie ‘m1’ with all other movies by finding the distinct viewers of ‘m1’ and using that value to find fraction of common viewers for any other movie ‘m2’. Thus,
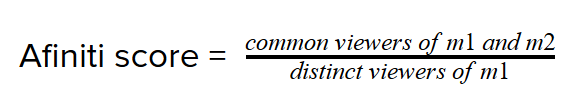
# empty dataframe for movie-movie afiniti score
movie_afiniti = pd.DataFrame(columns=[
'base_movieId',
'base_movieTitle',
'associated_movieId',
'associated_movieTitle',
'afiniti_score'])
# get unique movies
distinct_movies = np.unique(ratings['movieId'])
# movieId of movie viewer watched
ref_movie = 10
m_data = ratings[ratings['movieId'] == ref_movie]
#compare m1 with every other movie in distinct_movies
for m1 in distinct_movies:
if m1 == ref_movie:
continue
# count distinct viewers of m1
m1_data = ratings[ratings['movieId'] == m1]
m1_viewers = np.unique(m1_data['userId'])
# find movies watched by same set of users to calculate afiniti score
m2_viewers = np.intersect1d(m1_viewers, [m_data['userId']])
# find common viewers of m2 and m1
common_viewers = len(np.unique(m2_viewers))
afiniti_score = float(common_viewers)/float(len(m1_viewers))
# update movie_afiniti score dataframe
movie_afiniti = movie_afiniti.append({
"base_movieId": ref_movie,
"base_movieTitle": m_data.loc[m_data['movieId'] == ref_movie, 'title'].iloc[0],
"associated_movieId": m1,
"associated_movieTitle": m1_data.loc[m1_data['movieId'] == m1, 'title'].iloc[0],
"afiniti_score": afiniti_score
}, ignore_index=True)
movie_afiniti = movie_afiniti.sort_values(['afiniti_score'], ascending=False)
# For better recommendations, set afiniti score threshold
similar_movies = movie_afiniti[(movie_afiniti['afiniti_score'] > 0.6)]
similar_movies.sample(10)
By running the above association program, you will find movies often watched together with the referenced movie as output below:
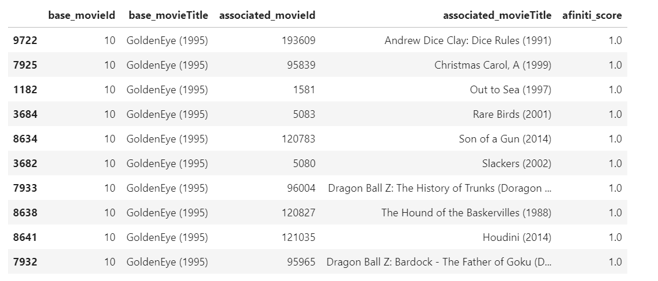
Result indicates that higher the afiniti score, the more viewers have watched the two movies together.
Another method to find association is ‘Lift value’ method that is the probability of items bought together divided by the product of individual probabilities of items.
Mathematically,
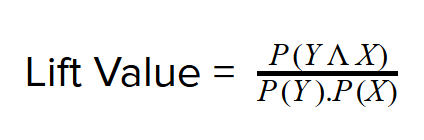
We just implemented a basic Product Association Recommender using a modification of Bayesian Theorem. The source code and the jupyter notebook is also available on our GitHub repo. Keep following to learn about more sophisticated recommenders!
Start Gowing with Folio3 AI Today
We are the Pioneers in the Cognitive Arena – Do you want to become a pioneer yourself?
Please feel free to reach out to us, if you have any questions. In case you need any help with development, installation, integration, up-gradation and customization of your Business Solutions. We have expertise in Deep learning, Computer Vision, Predictive learning, CNN, HOG and NLP.
Connect with us for more information at [email protected]

