




You’d like your computer program to be able to identify objects in an image, but also precisely model them, such as tracing their movements with a Digital Pen. This is what mask R-CNN can help you achieve.
Traditional methods of object detection, relying on techniques like shape recognition or basic image features, have encountered challenges. Such as.
- Occlusion: When objects are partially hidden behind each other.
- Background clutter: When the background has elements that resemble the object of interest.
- Small objects: When objects are very small in the image.
These methods often struggle with accurately distinguishing between objects with similar shapes or features and cannot provide fine-grained segmentation, hindering their performance in tasks requiring precise object delineation.
These limitations have led to the development of more sophisticated methods, such as RCNN (regions with CNN features).
R-CNN was a significant leap forward, using convolutional neural networks (CNNs) to extract features from image regions containing potential objects.
However, there were drawbacks to RCNN. Mask R-CNN builds upon Faster R-CNN, which addressed R-CNN’s speed limitations. Adds a critical element to the equation. Let’s take a look at the blog for further details.
What is Mask R-CNN:
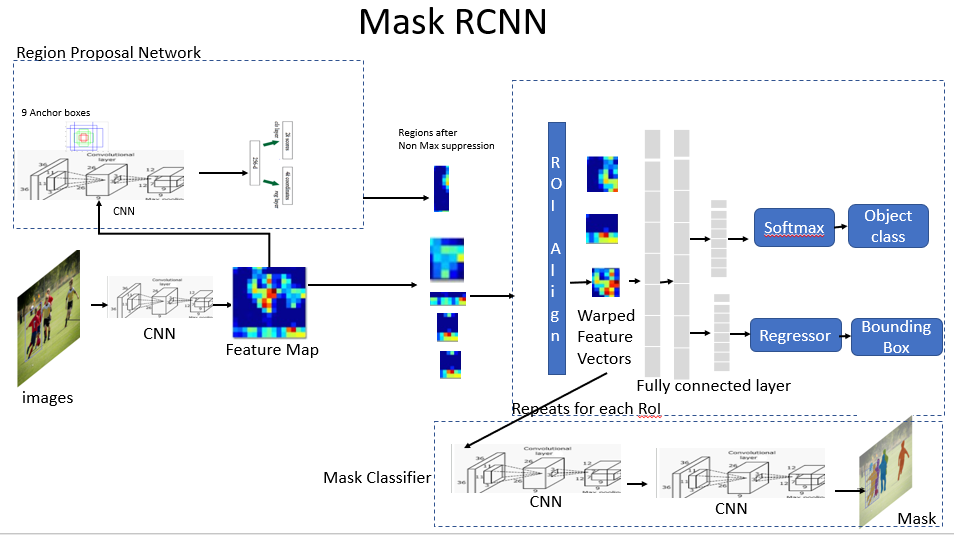
Mask R-CNN, short for Mask Region-based Convolutional Neural Network, is a powerful tool in computer vision for a specific task like instance segmentation.
This means that, in addition to detecting objects in the image, it can also precisely identify the exact shape of each object, such as drawing a digital mask around it.
t builds upon earlier object detection models like Faster R-CNN, which excels at finding objects but only provides bounding boxes (rectangular areas) around them.
Mask RCNN goes a step further, guessing the special mask for each object. This mask is a black-and-white overlay that’s exactly like the shape of the object, separating it from its background pixel by pixel.
Imagine you have an image of a person and a cat. RCNN wouldn’t just tell you that there was a man and a cat, but it would also create precise digital images of each body to indicate where the object ends and its background begins.
This fine-grained detail makes Mask R-CNN valuable for tasks like self-driving cars (segmenting lanes and objects), medical image analysis (identifying and outlining organs), and even augmented reality (creating realistic overlays by understanding object shapes perfectly).

Foundational Concepts of Mask R-CNN
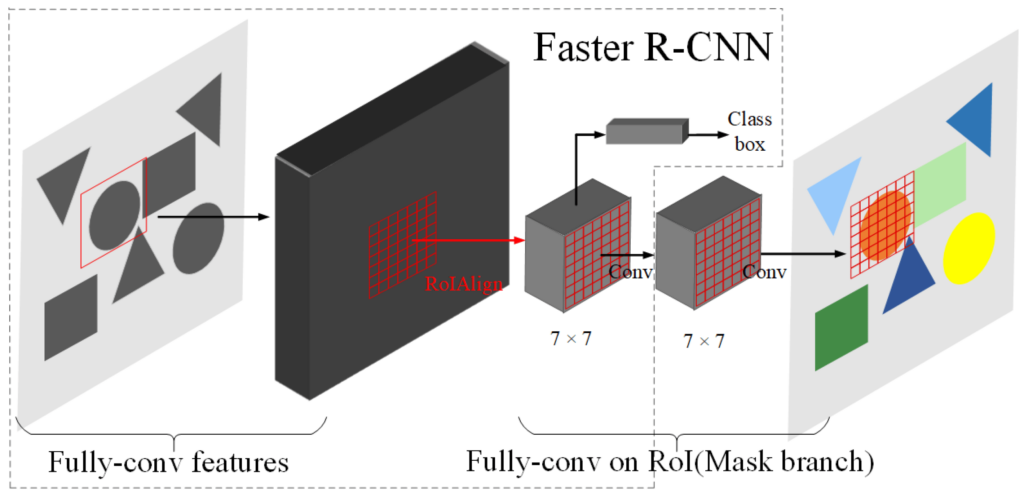
Understanding Mask R-CNN requires familiarity with three key concepts which are object detection, convolutional neural networks (CNNs), and region proposal networks (RPNs). Let’s break down each of these.
- Object Detection: Object recognition is intended to locate and identify objects in an image. Traditional methods were based on features such as shapes or simple color schemes. However, challenges such as occlusions, hidden objects, background clutter, and small objects have plagued these methods. Advanced techniques, such as convolutional neural networks, are used to achieve high accuracy in modern object detection, such as Mask RCNN. In this case, the aim is not only to identify the presence of the object but also to specify its location, usually with a bounding box and its category.
- Convolutional Neural Networks (CNNs): CNNs are highly sophisticated artificial neural networks specially developed for image analysis. They’re particularly good at recognizing patterns and shapes in images. It’s very good at learning complex patterns from vast training data, making it a cornerstone of modern computer vision tasks such as object detection. Here’s a more detailed breakdown of how these CNNs work.
- Layers: A CNN comprises multiple layers, each containing artificial neurons that process information.
- Filters: These layers apply filters that scan the image, extracting features like edges, lines, and shapes.
- Feature Maps: As the CNN processes the image, it generates feature maps that highlight these extracted features.
- Classification: In the final stages, CNN uses these feature maps to classify the image content and potentially identify objects.
- Region Proposal Networks (RPNs): Although CNNs are very good at the extraction of features, they can be computationally expensive to use for object detection, especially when scanning the entire image for potential objects. That’s where the RPN comes in. A Region Proposal Network (RPN) is a sub-network within a larger object detection model like Mask R-CNN. Think of RPNs as a way to efficiently identify areas of interest within the image that are likely to contain objects. These selected regions move on to the next parts of the model for identifying objects. In Mask R-CNN, this also involves segmenting objects.By putting all these pieces together, Mask R-CNN does a great job at spotting objects and outlining them, giving us a clearer picture of what’s happening in images. Let’s dive into what RPNs do.
- Input: The RPN takes feature maps generated by the CNN as input.
- Candidate Boxes: It analyzes these feature maps and proposes rectangular regions (bounding boxes) that might contain objects.
- Efficiency: By focusing on specific image regions, RPNs significantly reduce the computational cost compared to scanning the entire image.
Mask R-CNN Architecture Overview
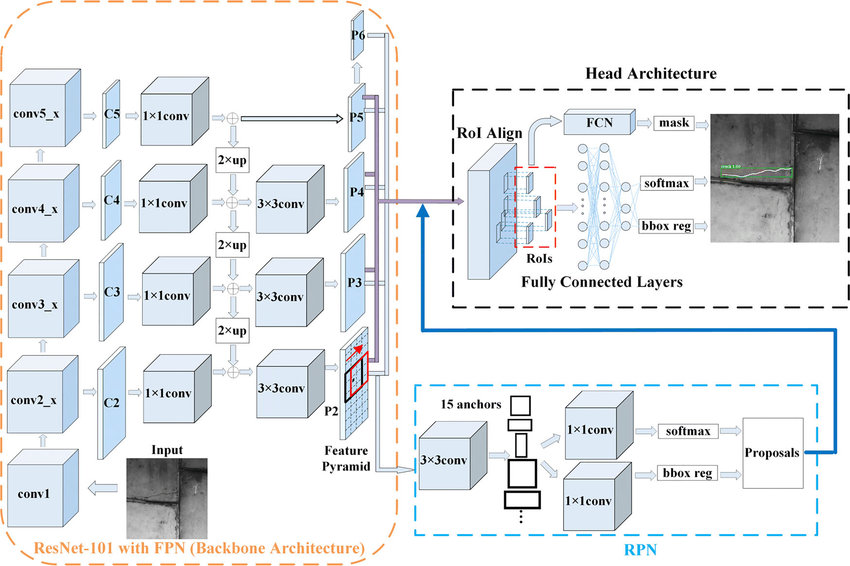
Mask R-CNN builds upon Faster R-CNN, adding a branch specifically for predicting segmentation masks. Here is a breakdown of its architecture, including key components.
-
- Backbone Network: The first stage utilizes a pre-trained convolutional neural network (CNN) like ResNet or InceptionV2. It acts as a base, extracting rich visual features from the input image.
- Feature Pyramid Network (FPN): Mask R-CNN brings in the Feature Pyramid Network (FPN) because objects in images can come in various sizes. FPN uses the backbone network’s feature maps to create a set of feature maps at different scales, like a pyramid. This way, it captures details important for both big and small objects in the image.
- Region Proposal Network (RPN): The RPN works on every level of the FPN pyramid, examining features to suggest potential bounding boxes for objects. By doing this, it uses the multi-scale features from the FPN to enhance the accuracy of proposals for objects of different sizes.
- Region of Interest (ROI) Pooling: The suggested bounding boxes from the RPN, also known as Regions of Interest (ROIs), are passed into another sub-network. Previously, ROI pooling was utilized to extract features from these ROIs. However, ROI pooling could sometimes lead to misalignment between the extracted features and the real object because of quantization, where values are rounded down to the nearest integer.
- ROI Align: To address this limitation, Mask R-CNN utilizes ROI Align. This is a more sophisticated method that uses bilinear interpolation to precisely align the extracted features with the corresponding regions within the image. This ensures accurate feature representation for each potential object.
- Classification and Mask Prediction Heads: The ROIs, along with their corresponding features from ROI Align, are fed into two separate heads.
- Classification Head: This head predicts the class label (e.g., car, person) for each ROI and its corresponding confidence score.
- Mask Prediction Head: This head predicts a binary mask for each ROI. This mask is like a high-resolution segmentation map that precisely outlines the shape of the object within the bounding box.
Overall Workflow
- The image is fed through the backbone network, generating feature maps.
- The FPN processes these feature maps to create a multi-scale feature pyramid.
- The RPN operates on each level of the pyramid, proposing candidate bounding boxes.
- ROI Align extracts precise features for each proposed bounding box.
- The classification head predicts object class and confidence score.
- The mask prediction head generates a segmentation mask for each object.
Mask R-Cnn Training Process
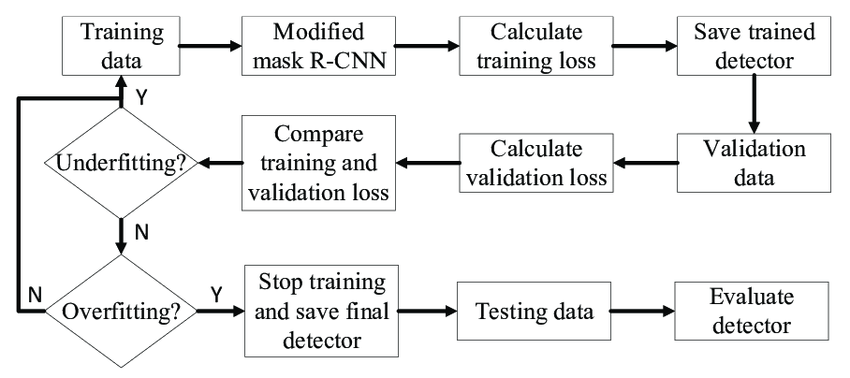
Careful consideration should be given to data preparation, loss functions, and optimization techniques when training the Mask RCNN model. Let’s take a look at the key elements:
-
-
-
- Data Preprocessing and Augmentation: High-quality annotated data is essential for training Mask R-CNN effectively. This data consists of images with bounding boxes around objects and corresponding pixel-level segmentation masks for each object instance. Here is how we prepare the data.
- Preprocessing: To ensure consistency during training, images can be resized and adjusted accordingly.
- Augmentation: To artificially expand the ML dataset and improve the generalization of the model, techniques such as random cropping, flipping, and color jittering are used. This makes it easier for the model to recognize objects under different situations.
- Loss Functions for Multi-tasking: Mask R-CNN performs two tasks simultaneously: object detection and segmentation. To guide the learning process, a combination of loss functions is used.
- Classification loss: For each object, the difference between the expected class labels, such as car, person, and ground truth, shall be measured.
- Bounding Box Regression Loss: Quantifies the discrepancy between the predicted bounding boxes and the actual object locations in the image.
- Mask segmentation loss: evaluates the difference between a predicted binary mask for each object and ground truth segmentation masks. This loss function ensures the model generates accurate and detailed segmentation masks.
- Fine-tuning and Hyperparameter Tuning: Training a complex model like Mask R-CNN often involves fine-tuning and hyperparameter tuning.
- Fine-tuning: You can kickstart with pre-trained models like ResNet. Here, the early layers stay fixed, and only the later layers, tailored for Mask R-CNN, get trained. This way, you make the most of pre-trained features while fine-tuning the model for object detection and segmentation tasks.
- Hyperparameter Tuning: Hyperparameters such as learning rate, optimizer settings, and the number of training epochs plays a big role in how well the model performs. To find the best setup, you can try techniques like grid search or random search. These methods help pinpoint the ideal hyperparameter configuration for your specific task.
- Data Preprocessing and Augmentation: High-quality annotated data is essential for training Mask R-CNN effectively. This data consists of images with bounding boxes around objects and corresponding pixel-level segmentation masks for each object instance. Here is how we prepare the data.
-
-
Overall Training Process
- Prepare the training data with preprocessing and augmentation.
- Define the Mask R-CNN architecture and loss functions.
- Choose an optimizer and set appropriate hyperparameters.
- Train the model by iteratively feeding it batches of training data.
- Monitor the training progress using metrics like average loss and validation accuracy.
- Fine-tune the model or adjust hyperparameters if needed.
Mask R-CNN Real-World Applications
Mask R-CNN’s ability to not only detect objects but also precisely outline their exact shape (instance segmentation) has revolutionized various industries. Here’s a glimpse into its impact across four key domains:
- Redefining Safety in Autonomous Vehicles: Self-driving vehicles rely on a precise understanding of their surroundings. Mask RCNN is excellent at detecting and segmenting objects such as pedestrians, vehicles, or markings on the road. This detailed segmentation allows the car to differentiate a person from a fire hydrant or a stopped car from a parked one, enabling safe navigation in complex environments.
- Traffic Management: In traffic camera footage, transport authorities use Mask RCNN for automatic identification of segment vehicles. This facilitates real-time analysis of traffic flows, the identification of accidents as well as automatic counting of vehicles to improve road management.
- Retail Security: Retailers enhance security measures by implementing Mask R-CNN for the detection and monitoring of stolen items. This system identifies suspicious activities and triggers alerts, helping to deter theft and bolster store security. Additionally, Mask R-CNN can group objects carried by customers, aiding in efficient monitoring and further enhancing security measures.
- Medical Diagnosis: Mask RCNN is best when it comes to medical image analysis. It’s able to break down tumors, organs, and other structures with great accuracy for earlier diagnosis, better treatment planning, or more effective surgical procedures.
- Immersive Augmented Reality Experiences: Precise object segmentation is crucial for creating realistic augmented reality (AR) experiences. Mask R-CNN allows virtual objects to be seamlessly integrated into the real world. Imagine virtually trying on clothes that perfectly conform to your body shape or placing virtual furniture that precisely interacts with existing objects in your room.
Mastering Mask R-CNN: Essential Tips
Extracting the most out of Mask R-CNN requires a strategic approach across all stages, from deployment training.
You can effectively train, deploy, and keep improving your Mask RCNN models through these guidelines to unlock their applications’ potential in a realistic world. To help you, here are the five main subheadings:
-
-
-
- Optimizing Training Efficiency:
- Make use of pre-trained weights on a strong backbone network like ResNet. This will give a strong foundation and shorten the training period.
- Use random cropping, rotation, and color jittering to expand your database. This will improve the model’s ability to recognize objects under different conditions.
- Deployment Strategies
- For real-time applications, choose GPUs or specialized hardware accelerators for efficient inference.
- Package your model and dependencies into a container (like Docker) for easy deployment and management across environments.
- Continuous Learning
- Engage with online communities like forums or subreddits dedicated to deep learning and computer vision. Learn from others and share experiences.
- Monitor your model’s performance and refine it by testing different hyperparameters such as learning rate or optimizer settings.
- Stay Updated
- Follow prominent deep learning researchers and publications to stay abreast of the latest advancements in Mask R-CNN and related techniques.
- Keep an eye out for state-of-the-art methods and experiment with them to see if they improve the performance of your model.
- Learn from Examples
- Utilize online tutorials and code examples to implement Mask R-CNN with different frameworks. This hands-on exploration deepens your understanding and equips you with complex projects.
- Dive deeper into the details of Mask R-CNN and its variations by reading research papers. Understanding the underlying concepts helps you get a grasp of how to apply them in your projects.
- Optimizing Training Efficiency:
-
-
Conclusion
The Mask RCNN technology is constantly evolving, with potential applications that are much wider than the current examples. Its capabilities can be further strengthened as the researchers refine this model of Deep Learning. We can anticipate groundbreaking applications over the next few years. Imagine a world in which robots can interact with objects in warehouses, or where augmented reality seamlessly blends virtual objects into the real world. So stay curious and keep exploring!

Dawood is a digital marketing pro and AI/ML enthusiast. His blogs on Folio3 AI are a blend of marketing and tech brilliance. Dawood’s knack for making AI engaging for users sets his content apart, offering a unique and insightful take on the dynamic intersection of marketing and cutting-edge technology.




